

脱レガシーで変化に強い基幹システムの基盤を実現
長年の信頼と“現場理解力”による伴走支援
ローカルLLMを簡単に動かせる!
Docker Model Runner試してみた
Docker Model Runner試してみた
こんにちは、クラウド活用推進担当の榊原です。今回もよろしくお願いします
ChatGPTなどのLLMが当たり前のように使われるようになった昨今ですが、
どうしてもコストの問題や、データ保護・コンプライアンス問題がついて回ります。
そんなとき「自分だけの環境で動かせたらなぁ」と思ったことはありませんか?私はあります。
しかし環境構築やモデルの管理など、ハードルが高く感じてしまってなかなか手を出せずにいました。
そんなときに出会ったのが、Docker Model Runner。
Docker環境でコンテナのようにローカルLLMを実行できるという、かゆいところに手が届く代物です。
というわけで今回は、どれほど簡単にローカルLLMを動かせるのか、実際に試してみました。
(参考: Docker Model Runner)
Docker Model Runner(DMR)は、Docker環境でAIモデルを管理・実行するためのツールです。
Docker Hubから大規模言語モデル(LLM)を取得すれば実行できるので、複雑な環境設定を必要とせず、
Dockerコンテナを実行するような感覚で簡単にローカルLLMを利用できます。
またREST APIを提供しており、OpenAI互換のAPIエンドポイントを利用可能です。
2025年4月にベータ版として登場したDMRですが、この時点では主にMacのみ対応で、Windowsは準備中となっていました。
しかし2025年9月18日の一般提供開始に伴い、Windows版Docker Desktopでも使用可能になりました。
現在DMRで使用可能なLLMのモデルはDocker Hubで確認することができます。(参考: Docker Hub)
Gemma(Google)やLlama(Meta)など主要なモデルが提供されており、
モデルの規模としても70B(約700億)パラメータが扱える大規模なものから
270M(約1.35億)パラメータの軽量なものまでさまざまです。
今回は正式に使用可能となったWindows版Docker Desktopで、DMRを実際に使ってみようと思います。
・OS: Windows11 Pro
・Docker Desktop: Version 4.48.0
・メモリ: 16GB
1. Windows版Docker Desktopを起動
2. Settings > AIに移動します。
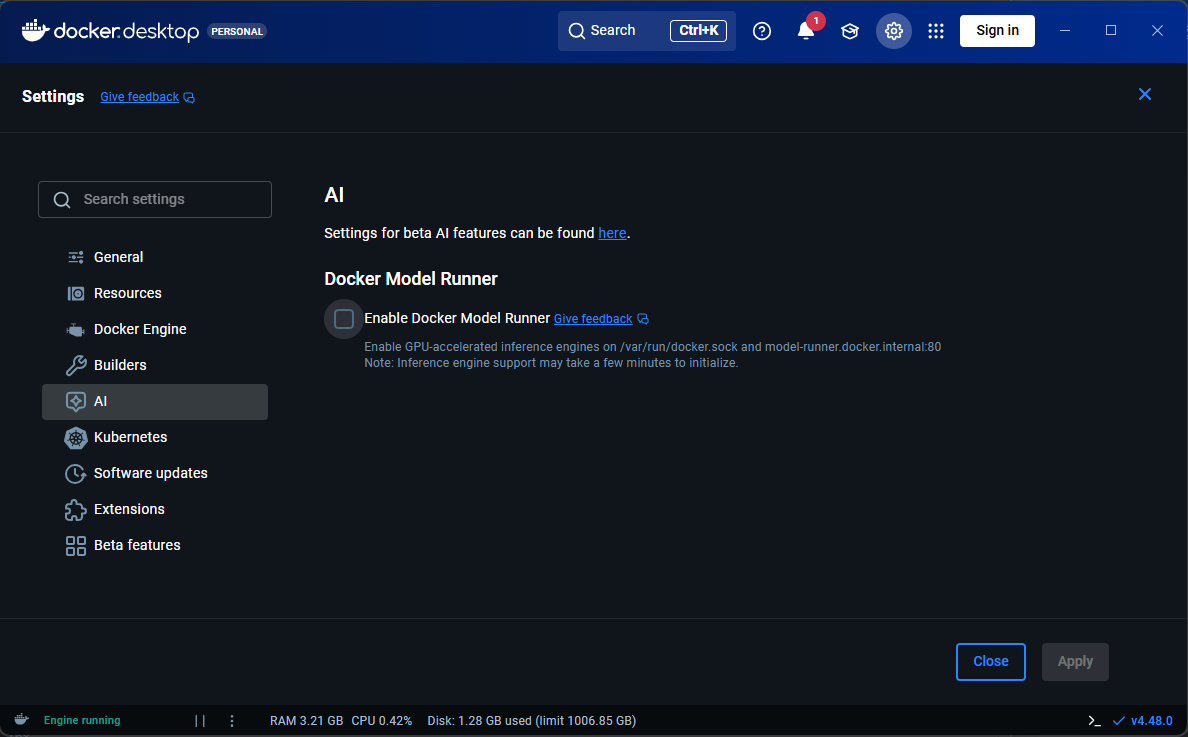
3. Enable Docker Model Runnerにチェックを入れます。
APIエンドポイントを利用するため、Enable host-side TCP supportにもチェックを入れておきます。
Portはデフォルトの12434を使用します。
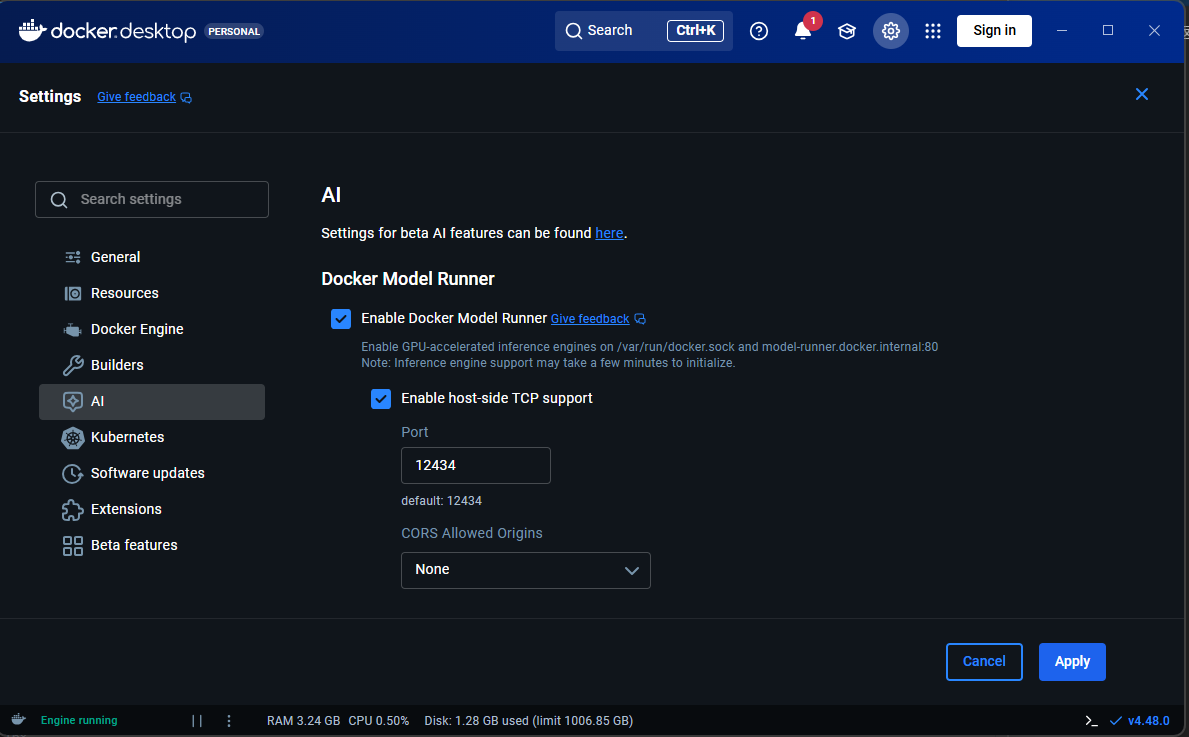
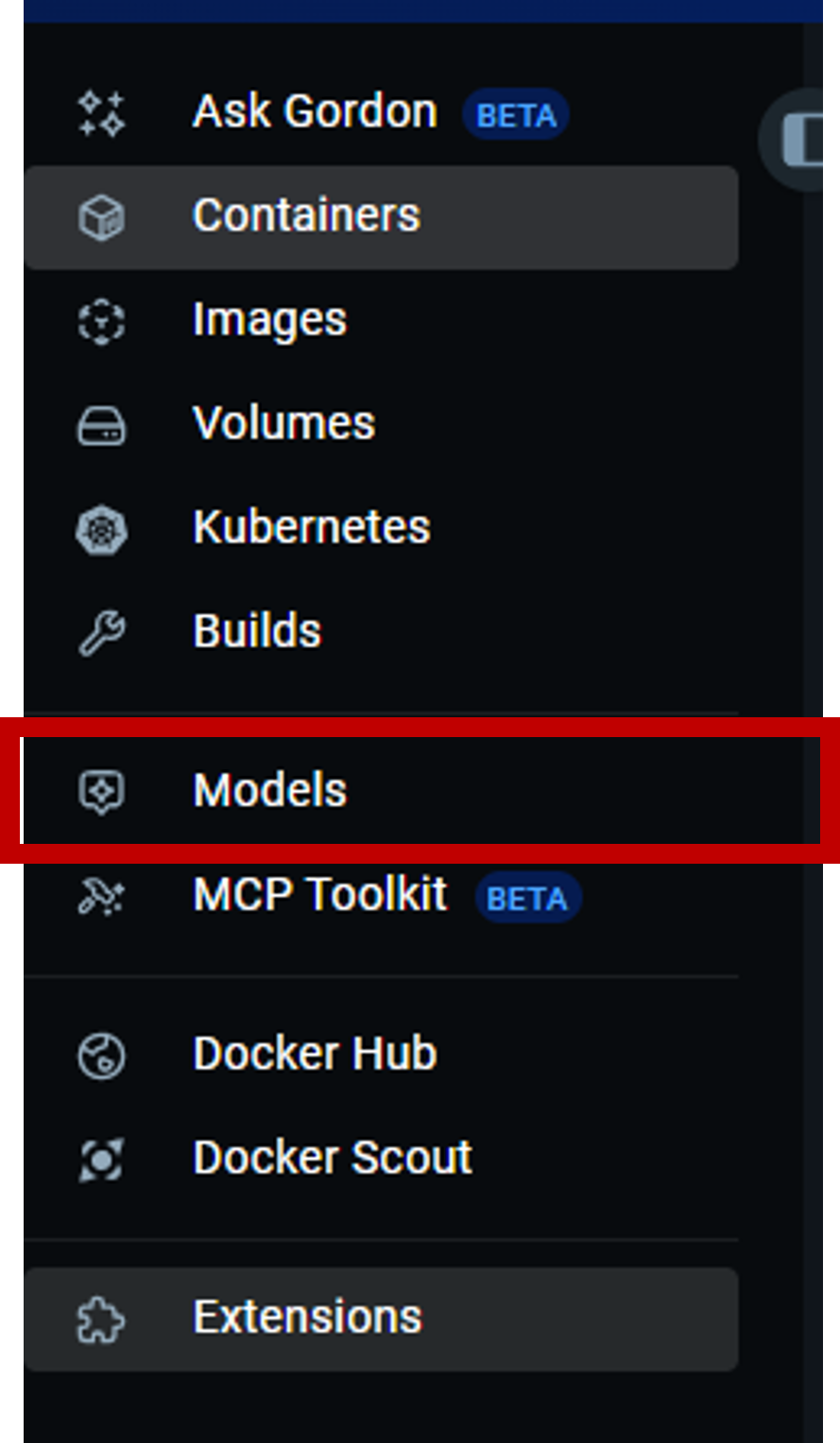
4. 設定を確認してApply。メニューにModelsが追加されているのを確認します。
1. Docker Hubのタブから任意のモデルを選択し、pullします。
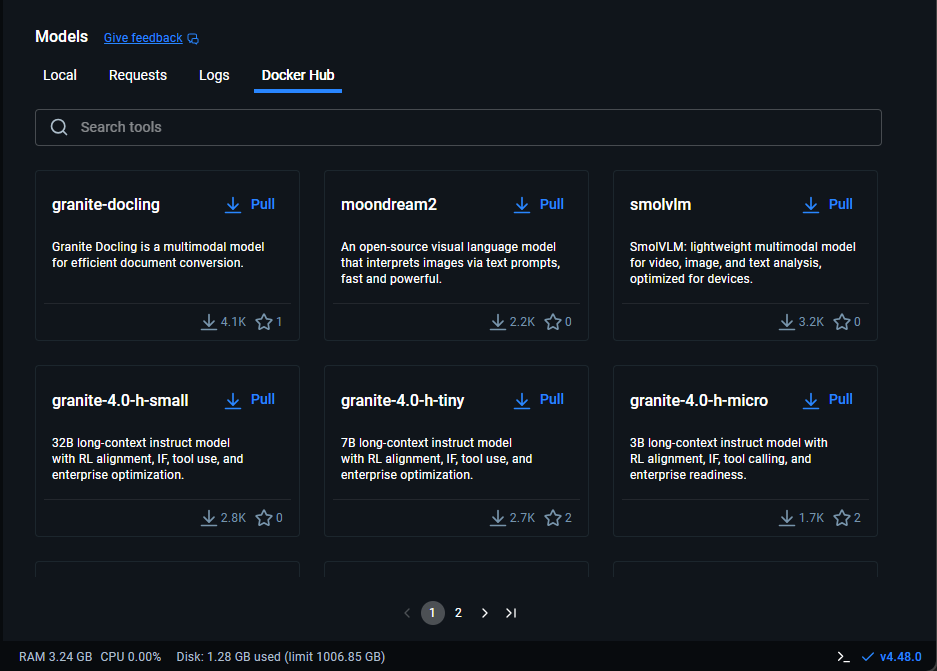
今回は、gemma3-qat:270M-UD-Q4_K_XLを選択しました。
270Mパラメータ、33Kトークンでサイズが240MiB程度の計量モデルです。

2. pullが完了したらRunから実行。
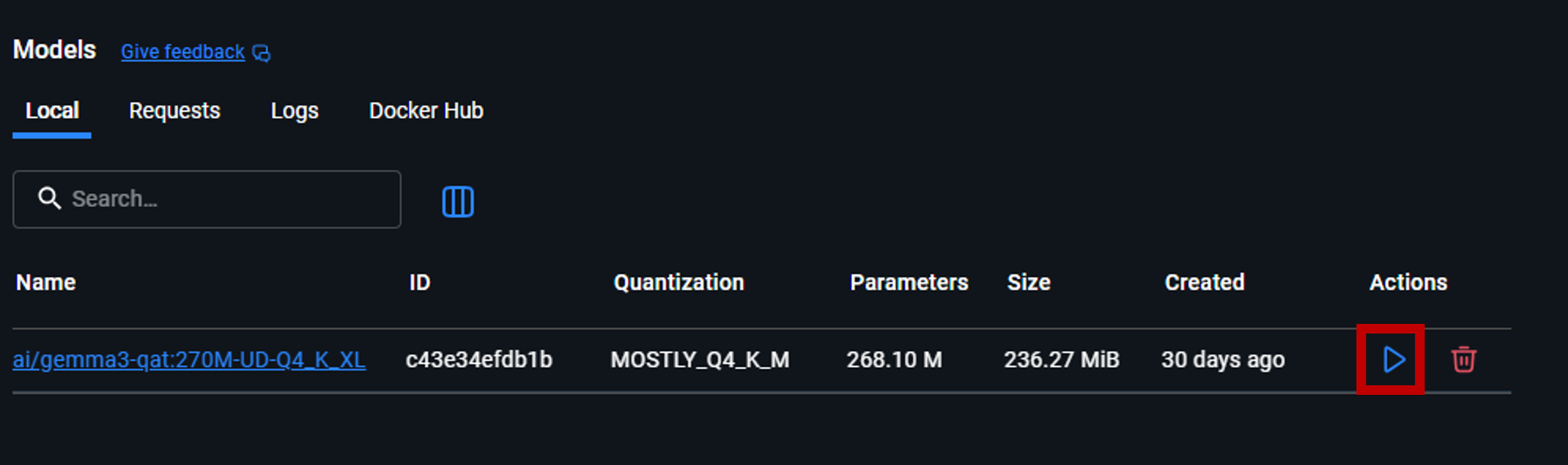
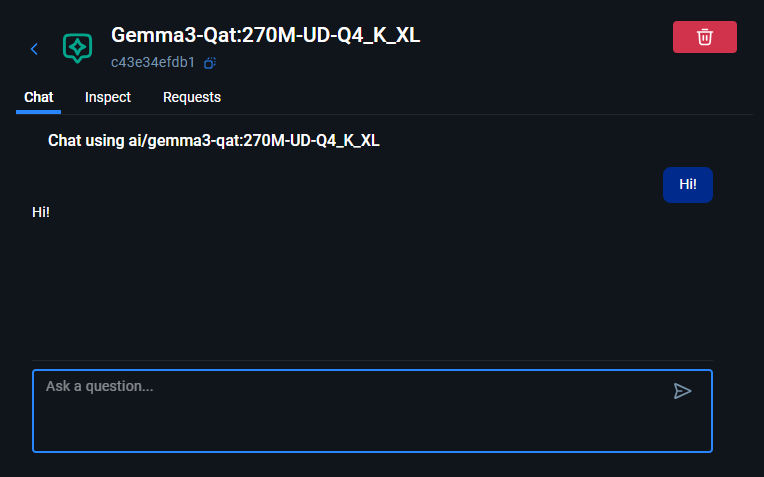
だけ。たったこれだけでローカルLLMを実行できます。
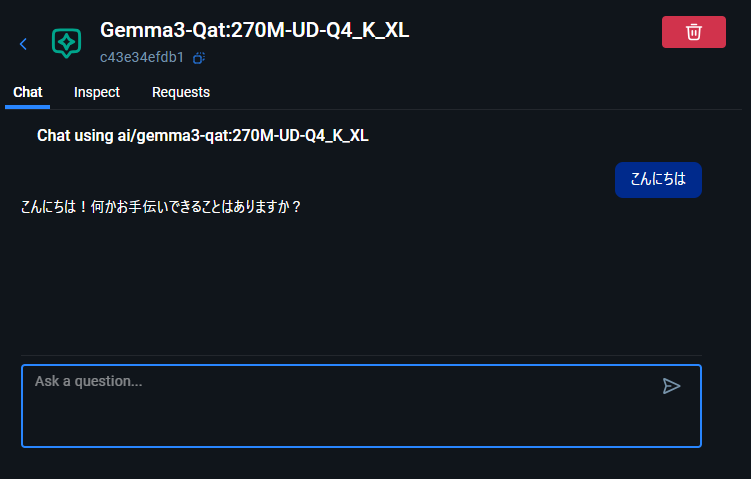
日本語もしゃべります。(対応言語はモデル依存)
前述のとおり、OpenAI互換APIが利用可能です。
アクセス元がDocker Networkの内部か外部かによってベースURLが変わるため、どちらも試してみます。
(参考: DMR REST API)
PowerShellからシンプルなリクエストを送ってみます。
URLはlocalhost、ポート番号はDMRを有効化したときに設定したポート番号です。
こんな返答がきました。
Dockerコンテナを立ててcurlでリクエストしてみます。
URLはmodel-runner.docker.internal、ポート番号は不要です。
こんな返答がきました。
メリット: ローカルLLMを簡単に実行できる
DMRはローカルLLMの利用をサポートしてくれます。
ローカル環境で動作するため、データが外部に露出することがなく、オフラインでも利用できます。
またクラウドサービスのLLMのようにAPI利用料等が発生しないため、ランニングコストを気にする必要がありません。
こうした利点をGUIでの簡単操作で享受できるのは大きな魅力だと思います。
ローカルLLMの導入ハードルはかなり下がったんじゃないでしょうか。
API連携にも対応しているので、開発環境に簡単に組み込めます。1環境1LLMも夢じゃないですね。
デメリット: ローカル環境に強く依存する
DMRはDocker上で動作するため、WSLのメモリ設定など仮想化レイヤの制約に影響を受けます。
今回は軽量モデルを実行しましたが、より大規模なモデルを使いたい場合は、仮想化レイヤに十分なメモリを割り当てる必要があります。
そしてそのためには、より高性能なハードウェアが必要に……。
こうなるとクラウド提供のサービスのほうがお手軽安価かもしれません。
またローカルで動作するため、ネット上の最新情報や外部サービスのデータを直接扱うことはできません。
必要に応じて、MCPやRAGなど外部連携の仕組みを組み合わせて補う必要があります。
今回は一般提供が開始されたDocker Model Runnerを使ってローカルLLMを実行してみました。
自分だけのLLMがこれだけ簡単に利用できるのは驚きです。
ローカルゆえのデメリットはもちろんありますが、手元で動かせる安心感や閉じた環境で扱える自由度は、
クラウドサービスにはない魅力だと思います。
今回はWindows版Docker Desktopを使用しましたが、CLIでも利用可能です。
Docker Composeに組み込んで他のコンテナと一緒にデプロイすれば、開発環境に自然に組み込むこともできます。
ローカルLLMを動かしたい人にとって、DMRはちょうどいい入口になると思いますので、ぜひお試しください。
ここまで読んでいただき、ありがとうございました。