

脱レガシーで変化に強い基幹システムの基盤を実現
長年の信頼と“現場理解力”による伴走支援
Amazon BedrockのKnowledgeBaseを構築したら
Tokenがスパイクした話
Tokenがスパイクした話
こんにちは、クラウド活用推進の新倉です。
先日Amazon Bedrockで検証を行っていた際に予期しないTokenのスパイクが起こったため、今後のためのメモと情報共有のため記事化します。
この記事を読んでくれた皆さまが同じ失敗をしないために参考にしていただければ幸いです。
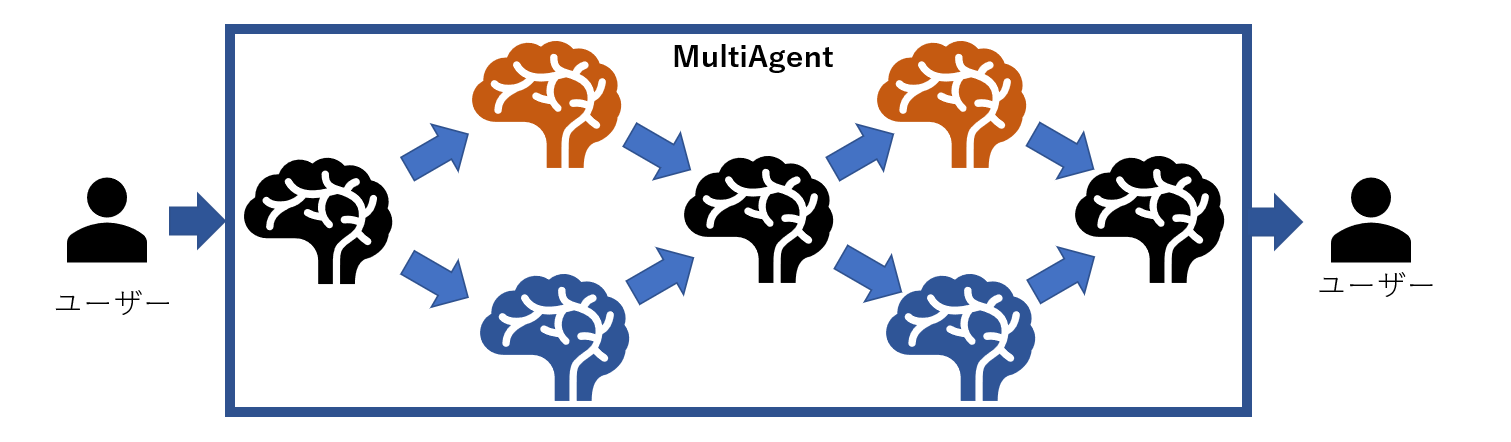
Amazon Bedrock AgentのMulti Agentを用いてQuickSightに詳しいAgentとPowerBIに詳しいAgentの二つを作成し、ユーザーのニーズに応じてより適しているサービスをAgent間で議論を交わしながら提案してくれるAIを作成しようと考えていました。
Multi Agentの流れ1
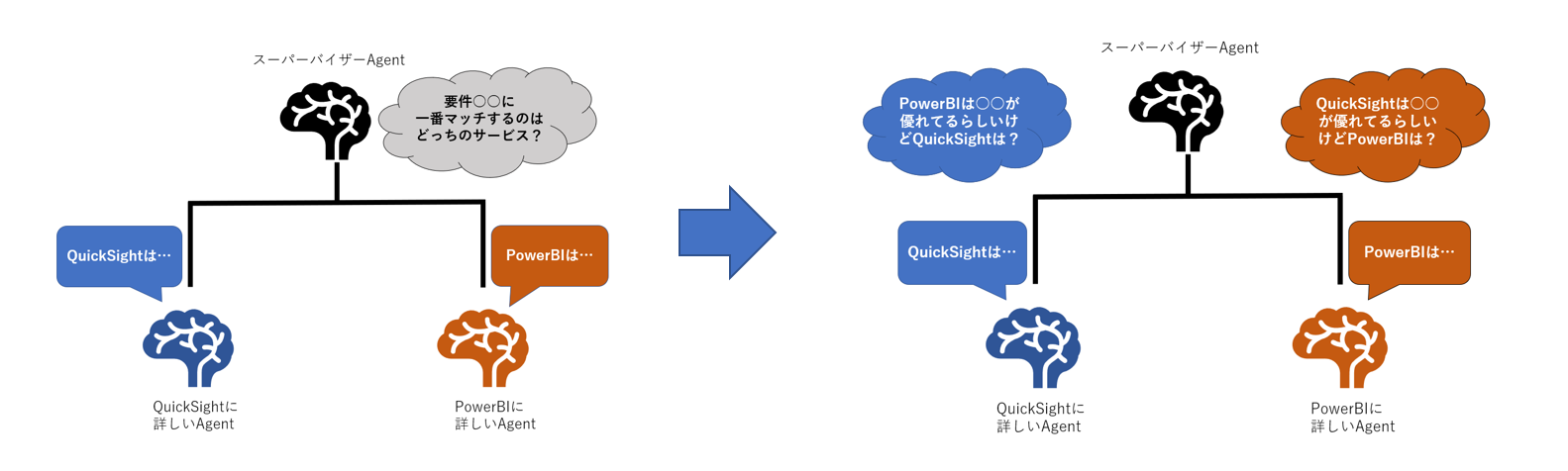
ユーザーの入力した用件に対してスーパーバイザーエージェントはそれぞれのサービスの専門家エージェントに自身のサービスを利用するメリットを聞き出します。
専門家エージェントは投げかけられた要件に自身の担当するサービスを利用する利点を生成し、スーパーバイザーエージェントに返答します。
スーパーバイザーエージェントはその返答を元に再度それぞれの専門家に質問を投げかけます。
このような形でそれぞれのサービスの専門家をスーパーバイザーエージェントを跨いだ形で議論させることが可能です。
Multi Agentの流れ2
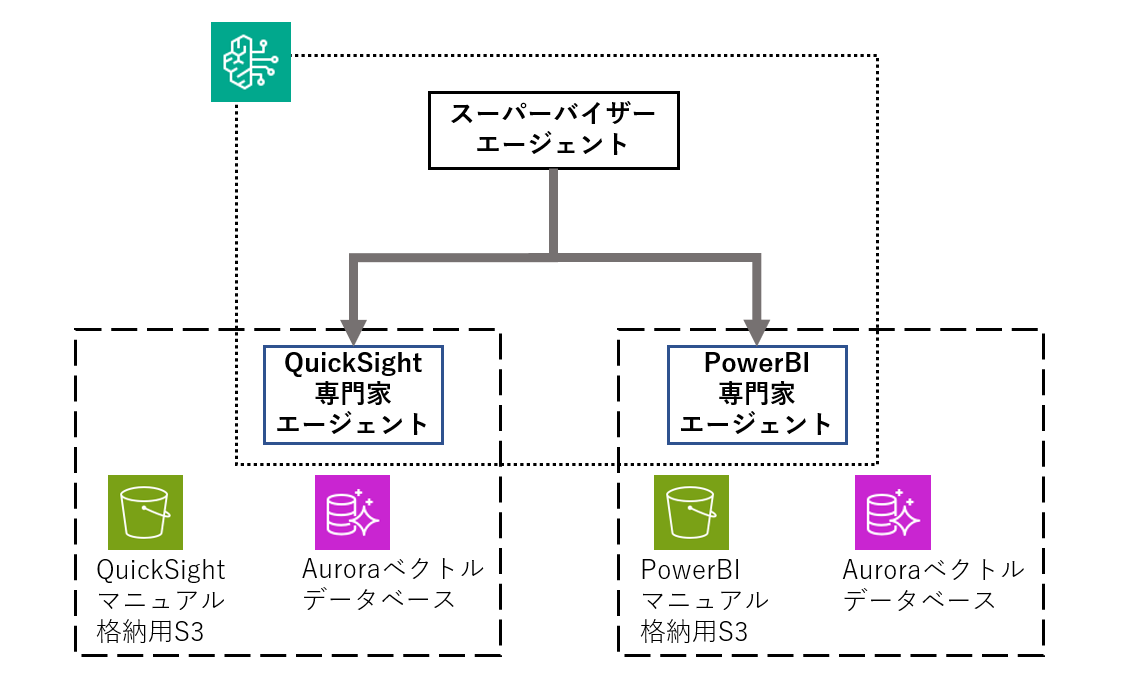
QuickSightとPowerBIのユーザーマニュアルをデータとして保持したRAG Agentの作成をおこないました。
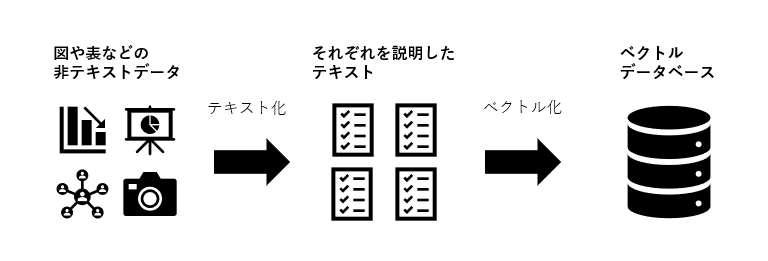
それぞれのマニュアルには図や画像などの非テキストが含まれているため、Advanced parsingを有効化したKnowledge Baseを保有したAgentを作成しました。
ベクトルデータベースはAuroraを設定し、それぞれのデータソースに各マニュアルを格納しました。
埋め込みモデルにはAmazon Titan Text Embedding V2をAdvanced parsing ModelにはAnthropic Claude 3.5 Sonnet v1.0を設定していました。
また各マニュアルは2101ページと448ページの物でした。
これらの設定でRAG Agentを構築しました。
RAG Agent簡易構成図
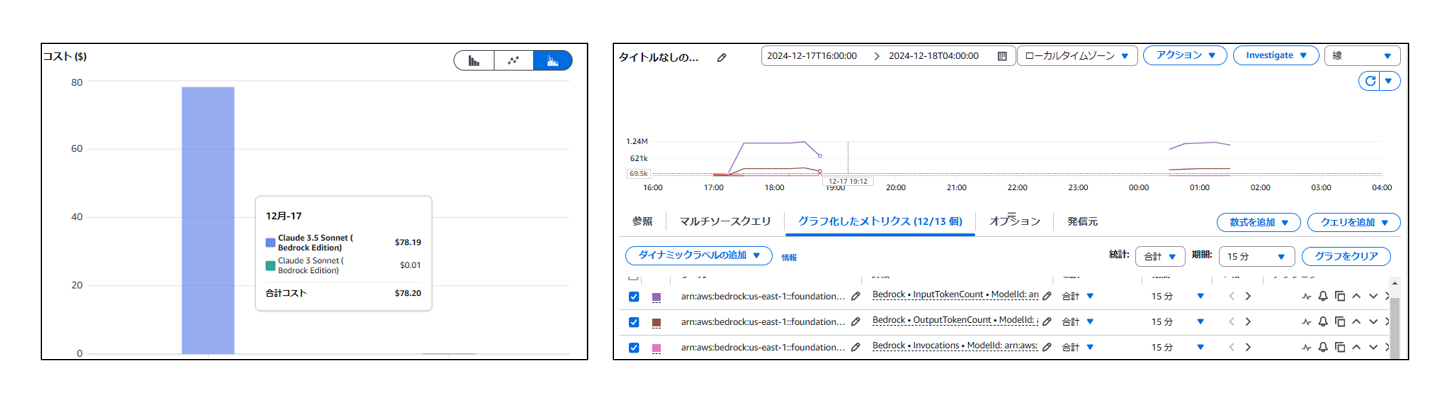
次の日、コストを確認するとClaude 3.5 Sonnet v1.0のInputTokenCostとOutputTokenCostが合計約80USDかかっていました。
またCloudWatchメトリクスではInputTokenが12,524,556、OutputTokeが2,701,224消費されていました。
Advanced parsingを有効化するとデータとして登録したPDFやWord、Excellなどをすべて画像として取り込み、全文をテキスト化したのちそのテキストをベクトル変換するようです。
今回のPDFでは1ページテキスト化するのに2000~4000Token消費されています。
てっきり非テキストデータのみを検出しAdvanced parsing モデルでテキスト化するのかと思っていたのですが、そうではなく全ページ全データをテキストに変換してしまうようです。
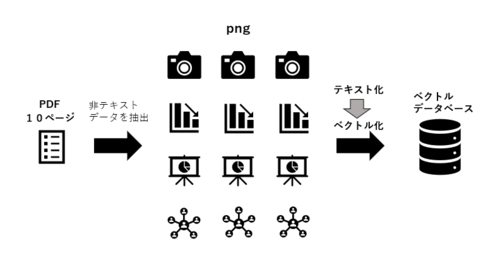
理想の流れ
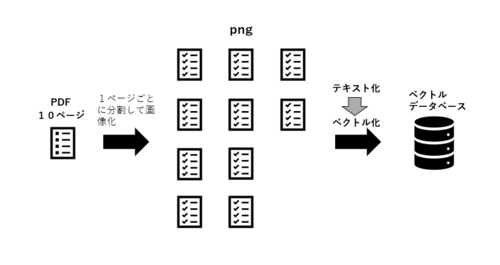
実際の流れ
今回Advanced parsingモデルにClaude3.5Sonnetを使用しましたが、その他にClade3Haikuも選択することが可能です。
Claude3HaikuはClaude3.5Sonnetに比べてTokenのコストが1/10程度なので検証やお試しで作成する際はこちらを使用すればコストは1/10になります。
ただしSonnetに比べ制度は落ちるため、精度を優先したい方はSonnetを選ぶか、Amazon NovaがKnowledge Baseに対応するのを待ちましょう。
またKnowledge BaseなどRAGを利用する際はLLMの消費Token数にアラートを設定しておくことをお勧めします。
CloudWatchから簡単に設定できるため、事故が起こる前に設定しておきましょう。
本検証では約2,500ページのPDFをソースとして使用しましたが、実際のユースケースではこの10倍、時には100倍以上のデータを扱う可能性があります。
このような状況下でコスト効率を最適化するには、各ユースケースに適したLLMを選択することが極めて重要です。
必要以上に高スペックなモデルを使用せず、目的に合った適切なLLMを選ぶことで、コストを抑制できます。
皆様もKnowledge Baseを利用する際はコストの監視を怠らず、適切な設定になっているのか注意して運用しましょう。