

脱レガシーで変化に強い基幹システムの基盤を実現
Azureクラウドへの移行で、俊敏な経営と業務改革を支える
【Amazon Bedrock】
GraphRAGと従来のRAGを使い比べてみた
GraphRAGと従来のRAGを使い比べてみた
こんにちは!クラウド活用推進担当の浅野です。
2025年3月7日、Amazon BedrockよりGraphRAGが正式にリリースされました。
それまではプレビュー版として提供されていましたが、正式にリリースされたという記事を見て、
改めてGraphRAGと従来のRAGでは生成結果にどのような違いが生まれるのか気になったので
調査していこうと思います!
RAG(検索拡張生成)は、LLM(大規模言語モデル)によるテキスト生成に
外部情報の検索を組み合わせることで、回答精度を向上させる技術です。
「ベクトル検索」と呼ばれる手法用いて、質問に対していきなり回答を生成するのではなく、
答えが書いてありそうなドキュメントを検索し、それを参照してから回答を生成します。
GraphRAGは、RAGに「※グラフデータベース」の要素を組み合わせた新しい仕組みです。
概念を「ノード」、関係性を「リレーション(エッジ)」として構造化することで、
情報同士のつながりを考慮した検索と生成が可能になります。
簡単に言うと検索した情報をただ使うのではなく、
・誰が誰を知っているか
・どの商品がどの商品と関連しているか
・あるアイデアが別のアイデアにどう影響したか
といった複雑な関係性を考慮してから回答を生成するRAGです。
※グラフデータベース:グラフ構造を備え、データ間の関係性を表現することができるデータベース
AWSではAmazon Neptuneでサービスが提供されています。
従来のRAGは、情報を細かく分割してベクトル化し、類似度に基づいて検索を行っていました。
そのため、データ間の「類似度」は把握できても、
「関係性」に関する情報を得るのは難しいという課題がありました。
一方で、GraphRAGはデータ間の関係性を表現できる
グラフデータベースとベクトルデータを組み合わせることで、
・データ間の「類似度」
・データ間の「関係性」
この両方の情報をもとに、より精度の高い回答の生成が可能になります。
これにより、従来のRAGでは難しかった踏み込んだ回答にも対応できるようになっています。
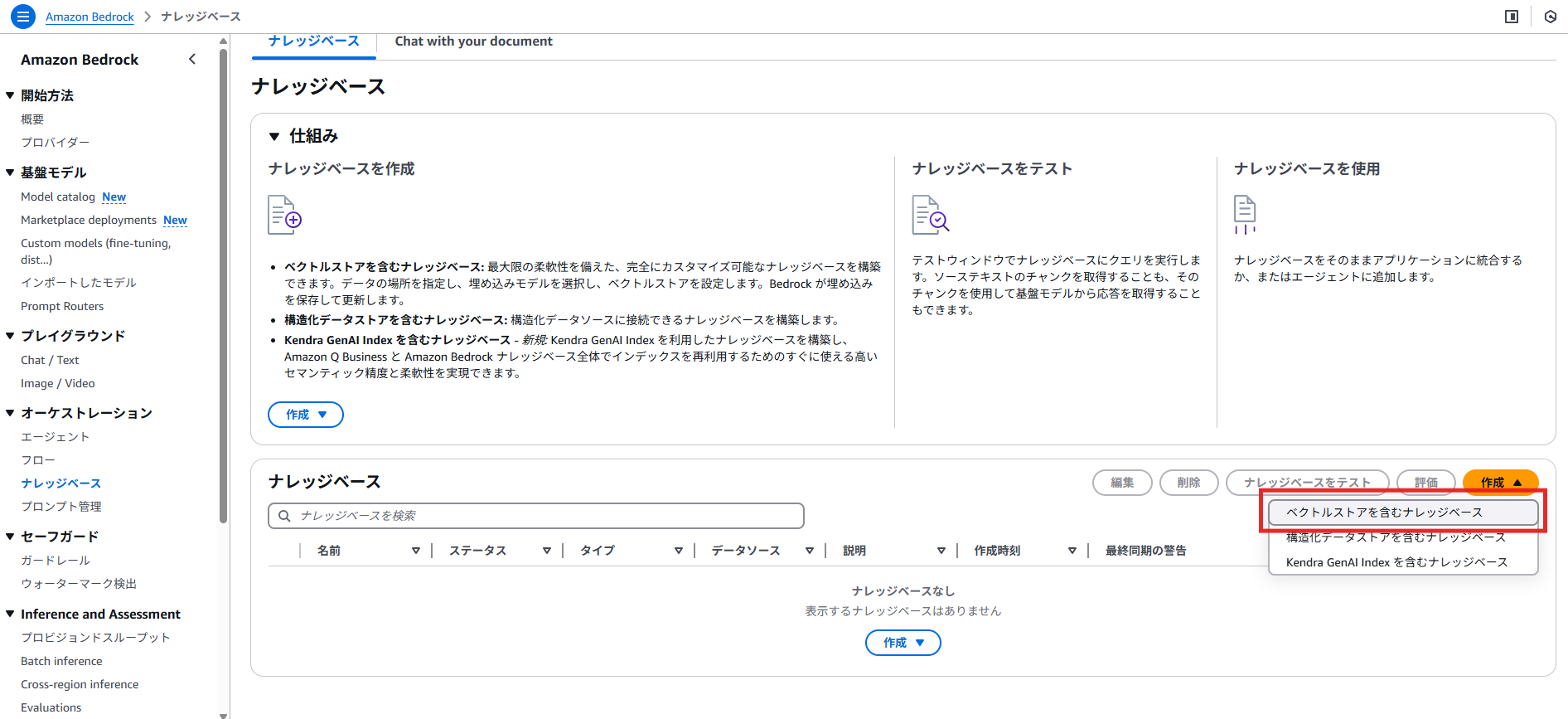
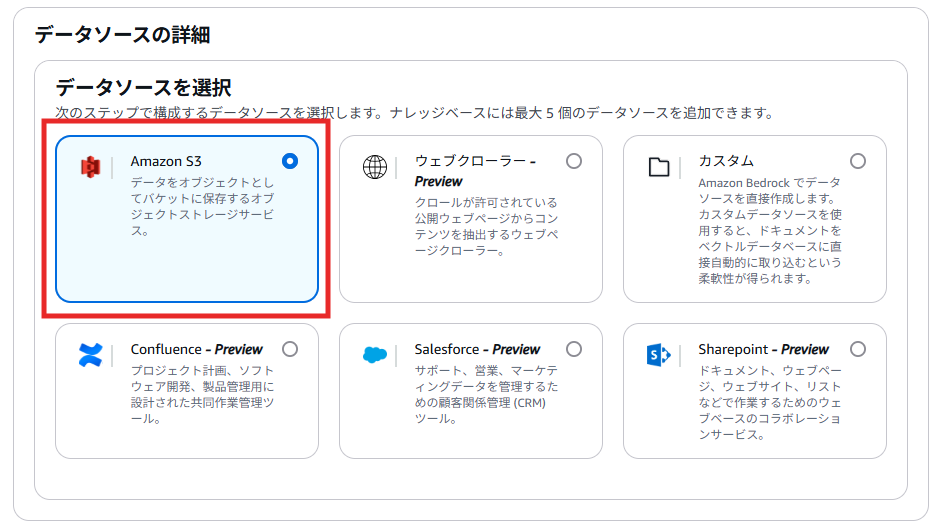
では、Amazon Bedrock上にGraphRAGを搭載したナレッジベースを作成していきたいと思います!
前提条件
・リージョン:us-east-1(バージニア北部)
・S3バケット:作成済み
・比較する従来のRAG環境:作成済み(作成方法は後述しています)

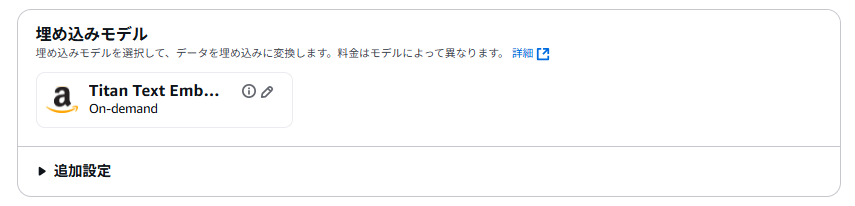
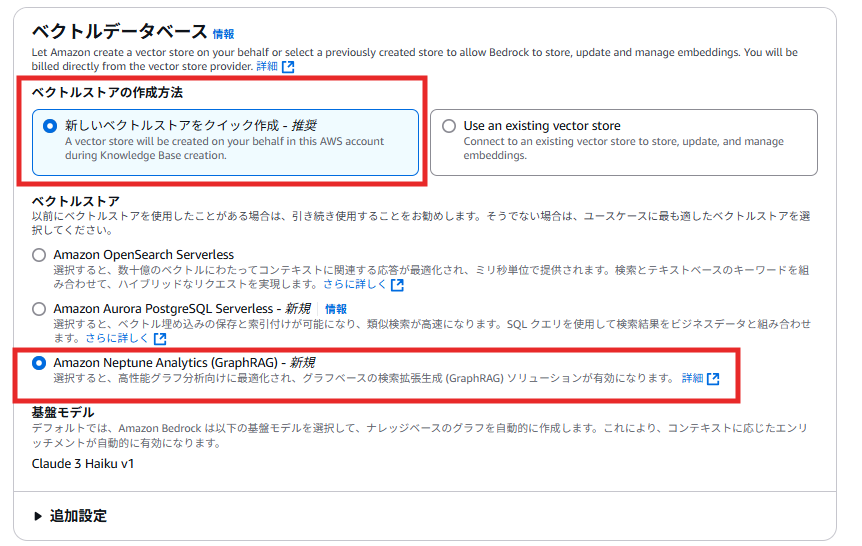
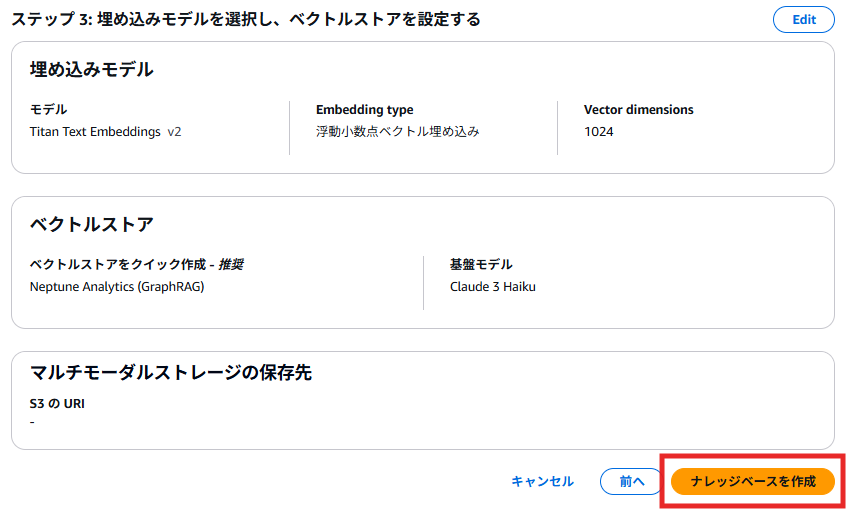


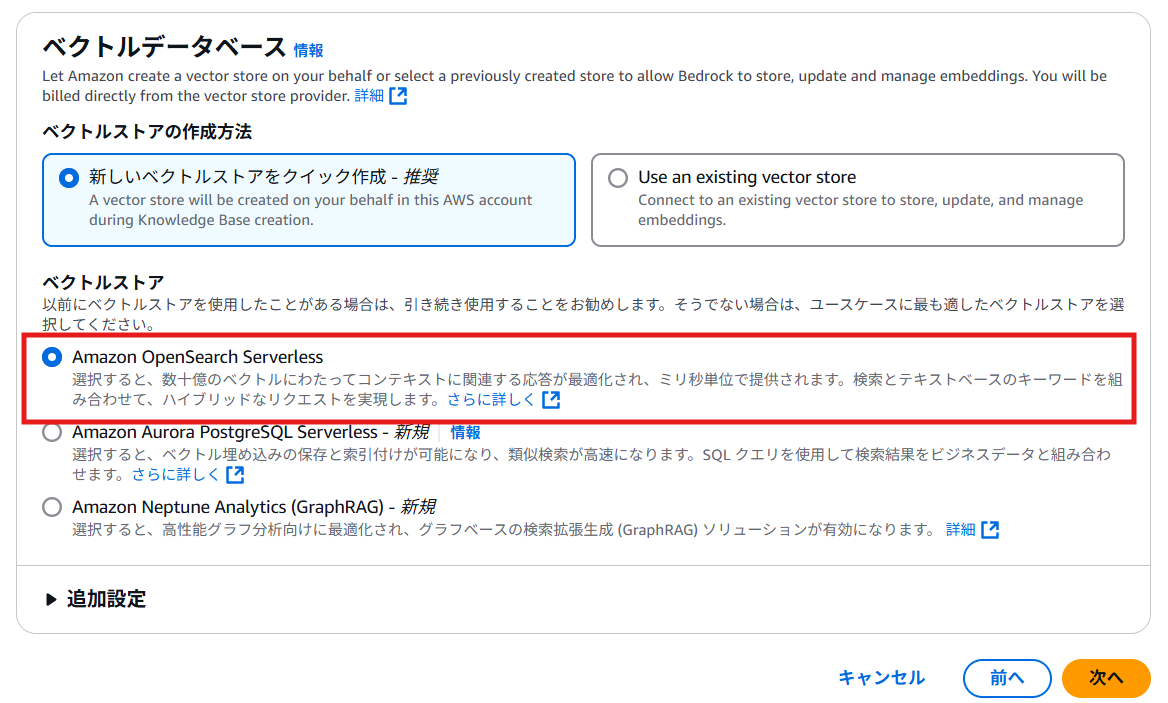
今回作成したGraphRAG搭載ナレッジベースと、比較対象として用意した
従来のRAG搭載ナレッジベースに全く同じ質問を投げて、
生成結果にどのような違いが生まれるかを比べてみたいと思います!
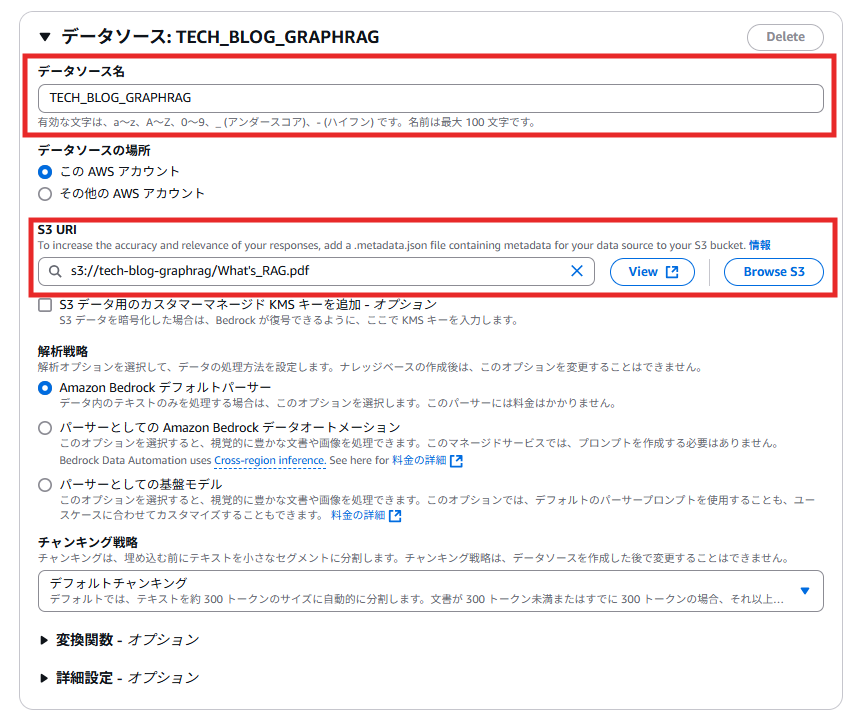
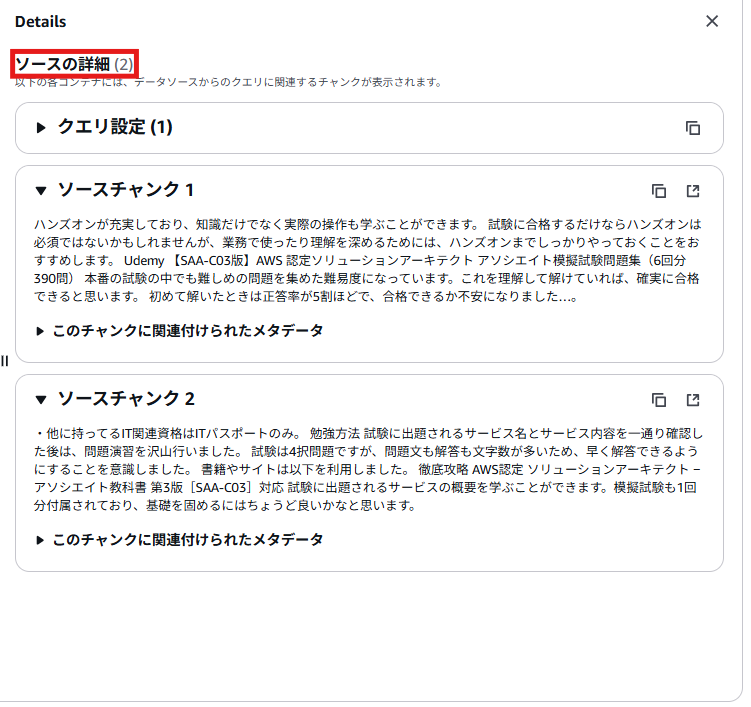
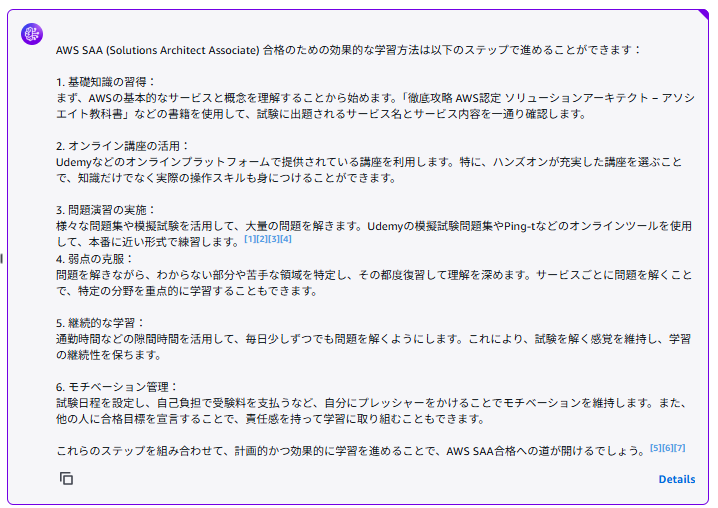
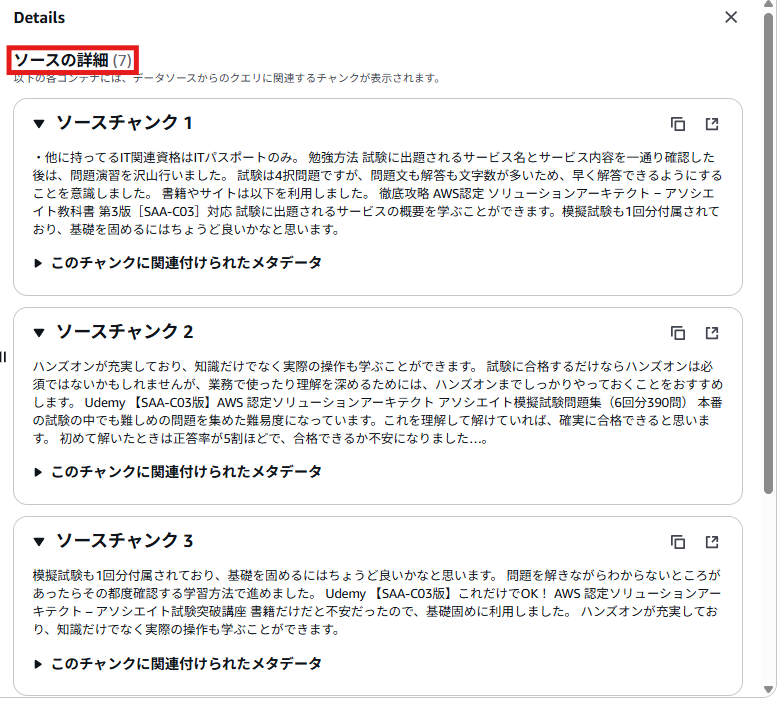
S3バケットに格納ておいた以下の技術ブログの内容について生成AIに質問してみました。
生成AIはClaude 3.5 Sonnetを利用しています。

Amazon Neptuneは、リソース作成後、最低でも0.48USD/1Hの費用が発生します。
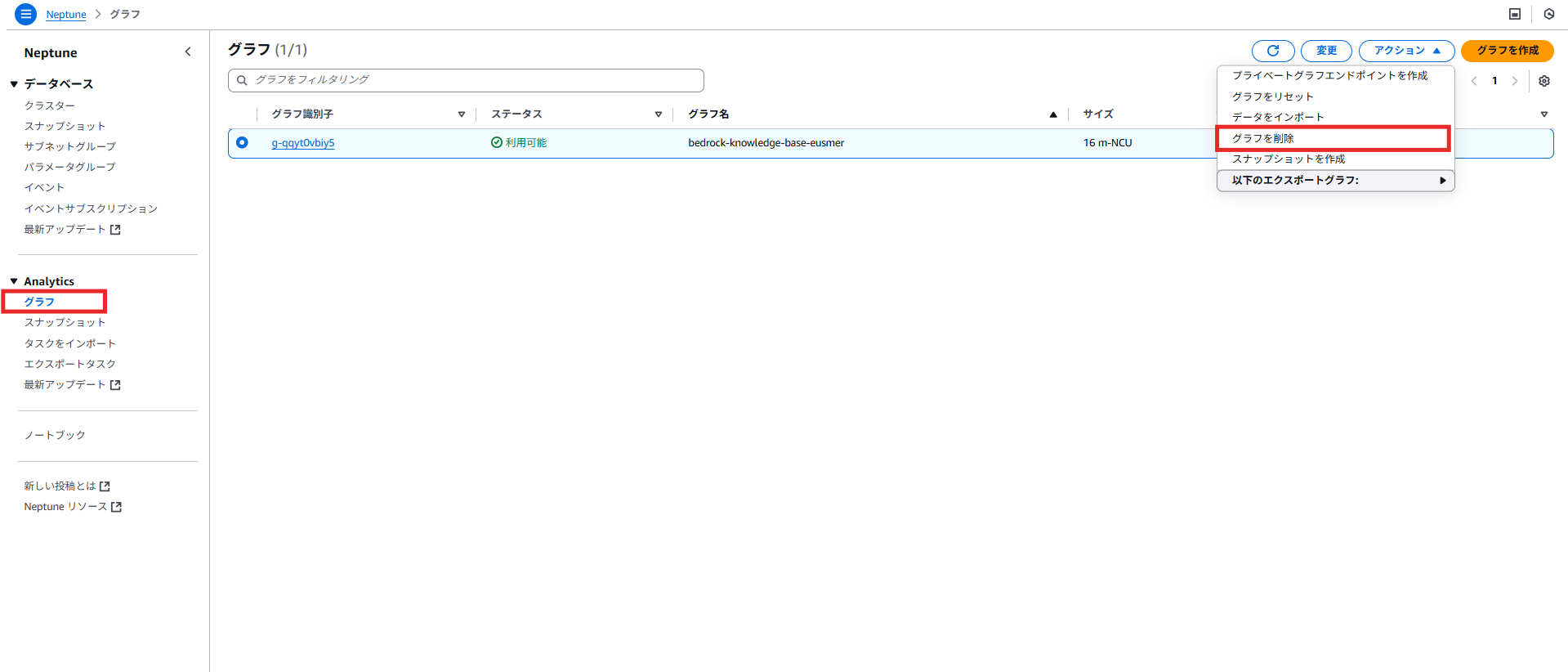
検証が終了したら、今回作成した以下のリソースを削除してください。
・Amazon Bedrock:作成したナレッジベースを削除
・Amazon Neptune:ナレッジベース構築時に作成されたグラフデータベースを削除
※比較対象としてRAGを搭載したナレッジベースを別途作成した場合は、
Amazon OpenSearch Service Serverlessに作成されたリソースも削除してください。
今回、GraphRAGと従来のRAGを比較してみて、出力結果にどのような違いが出るかを調査してきました。
その結果、
・理由や背景等の具体的な回答も含めて欲しいときはGraphRAG
・素早く簡易的な回答が欲しいときは従来のRAG
と、求められるユースケースで使い分けるのがいいと感じました。
GraphRAGは、文脈を理解し、データ間の関係性を考慮してから回答を生成してくれるので、
情報の深掘りや具体的な説明が欲しい場面に適しています。
一方で、従来のRAGは無駄のない回答を生成してくれるので、
必要な情報だけを求めるシンプルな回答が欲しい場面に適しています。
使いたいシーンやプロンプトの工夫次第で、さらに使い分けができそうなので、
引き続き調査を継続していきたいと思います!ご閲覧いただきありがとうございました!