

脱レガシーで変化に強い基幹システムの基盤を実現
Azureクラウドへの移行で、俊敏な経営と業務改革を支える
AI AgentのMemory機能を使って
議事録修正アプリを作成してみた。
議事録修正アプリを作成してみた。
DTS では、有志のメンバーが AWS に関する業務や学習で得た知見を社内で共有する「技術共有会」を開催しています。
先日、その活動の一環として、AWS Bedrock Agent の Memory 機能を活用した議事録修正 AI について紹介しました。
本記事では、そのシステムの詳細について解説します。
Memory 機能とは、AI とユーザーのやり取りを記憶する機能です。
Agentは、ユーザーがAgent と今まで行ったやり取りの情報をもとに、次回以降の会話でより適切な回答を生成できます。
例えば、ユーザーがエージェントに自身の名前を入力した時、Agentはそのやり取りを記憶します。これによって次回以降、回答の生成でユーザーの名前情報が必要な時、ユーザーが入力する必要はなくなります。
ユーザーと AI Agent の会話内容は、セッションが終了するタイミングで要約・保存されます。
セッションは、Agent を呼び出したタイミングで開始され、Agentが一定時間利用されなかった場合に終了します。
この時間は Bedrock の「アイドルセッションタイム」設定で制御できます。
セッションが終了すると、その会話内で話された内容が要約され、Memory に保存されます。
Agent Memoryではこれまで行われた会話のすべてが自動的に保存されます。
ユーザーは保存されたMemoryを削除することができます。
今回はこの機能を用いて議事録の誤字修正Agentを作成しました。
具体的にはTeamsなどのオンライン会議ツールで議事録を自動生成した時に発生する誤字の修正をAI Agentを用いて自動化しようと考えました。
従来のChatGPTなどの生成AIでも簡単な誤字修正は可能です。ですが、「情シス」や「クラ推(クラウド活用推進担当の略)」などの専門的な用語や、ある組織特有の単語には対応することができませんでした。
AI AgentのMemory機能を使うことでこういった単語にも対応した誤字修正を行うことが可能です。
このシステムの処理の流れは以下の通りです。

今回のデモで有効化した機能の中で、主要なものを解説します。
この機能はユーザーの質問にたいして、Agentが回答に必要な情報が不足していると判断した場合にAgentがユーザーに追加の情報を求めることができるようにします。
ユーザーが何も入力せずに、セッションがアイドル状態の場合にセッションを維持する時間を指定できます。今回のデモでは60秒に設定しました。
ユーザーとAgent間で行われた会話の内容をAgentが保存し、次回以降の会話で今回の会話の内容を踏まえた回答を生成することができるようになります。メモリの最大保存日数は365日です。
今回のデモでは会話の履歴の保存日数を30日間に設定しました。
ここではエージェントが実行するタスクやアウトプットのスタイル、Agentの役割などについて定義します。
今回は以下の文章を設定しました。
あなたは議事録を修正するためのアシスタントです。
以下の要件に従い、ユーザーが入力した議事録を修正してください。
・議事録の中に誤字があれば修正してください。
・議事録では特に専門用語を誤字している場合が多いです。例えば正しくは「情シス」なのに対して議事録では「上質」となってしまっているなど。このような誤字を修正するため文脈として違和感のある文字はユーザーへ正しい文字を確認してください。
・過去、ユーザーに確認したものに関しては次回以降、ユーザーに確認せずに修正してください。
・ユーザーに確認せずに修正するときは前後の文脈を確認し、修正が必要か否か判断してください。判断ができなければユーザーへ確認してください。例えば「情シスに確認」は正しい表現ですが「情シスな会議を行う」は非常に不自然な表現です。語句の意味と修正する語句の前後の文脈を踏まえて修正するべきか判断してください。
・すべての誤字を修正した後、議事録を読みやすく成形しユーザーへ返答してください。最終的にすべての修正点を修正した文章すべてをユーザーへ返答してください
今回のデモでは、エージェント向けの指示に「文脈を踏まえて修正の必要性を判断する」よう記載することで、不適切な誤字修正が行われないよう制御しました。
例えば、システムに関する打ち合わせでは「石鹸」を「設計」と修正するのは正しい動作ですが、大掃除の備品リストで同様の修正を行うのは誤りです。
このように、文脈によっては修正が不要な語句について、周囲の文脈を考慮して誤字修正を行うことで、より適切な修正が可能になります。
Teams WebhookとAWS Lambdaを用いてTeamsからAI Agentを呼び出す環境を構築しました。
以下が構成図になります。
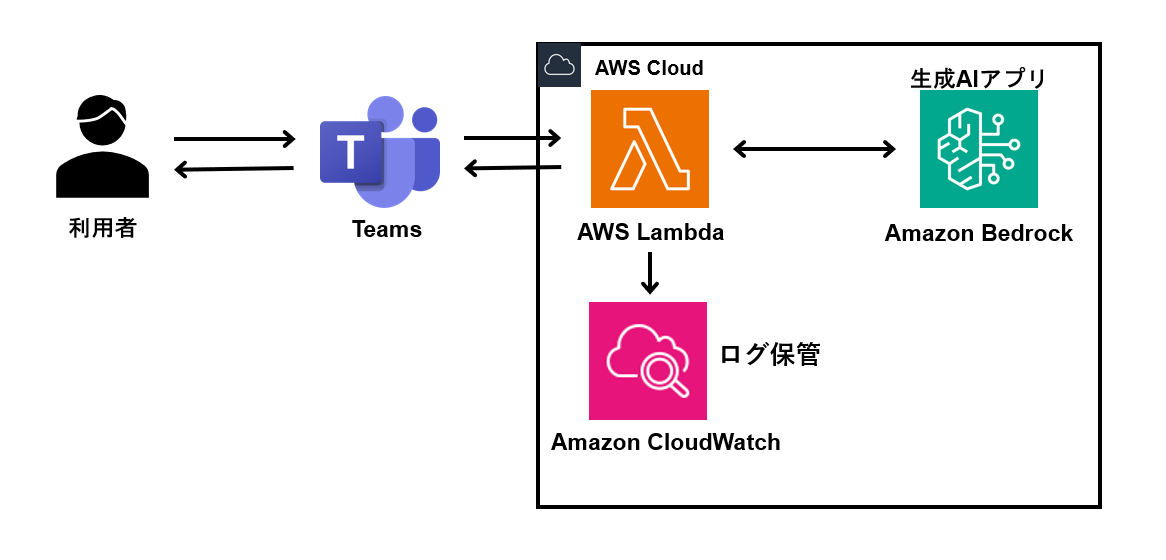
上記機能を設定したAgentを作成することで個人にパーソナライズされた誤字修正Agentを作成し、Teamsから呼び出すことに成功しました。
1.まず初めにTeamsでAgentを呼び出し、議事録の文章を送信します。
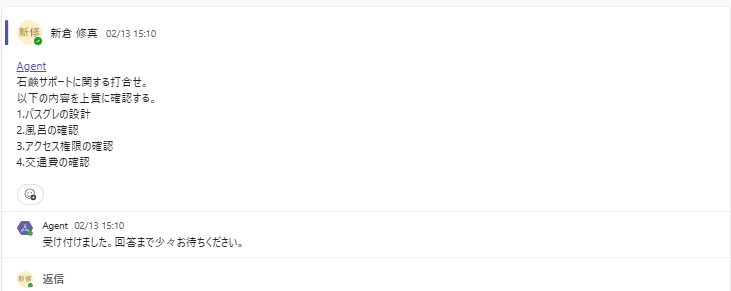 2.議事録の中に誤字の可能性のある文言があった場合、Agentから正しい文言を確認されます。
2.議事録の中に誤字の可能性のある文言があった場合、Agentから正しい文言を確認されます。
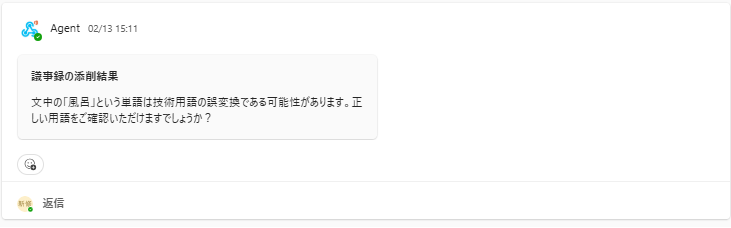 3.すべての確認がおわると、Agentから修正した議事録が送信されます。
3.すべての確認がおわると、Agentから修正した議事録が送信されます。
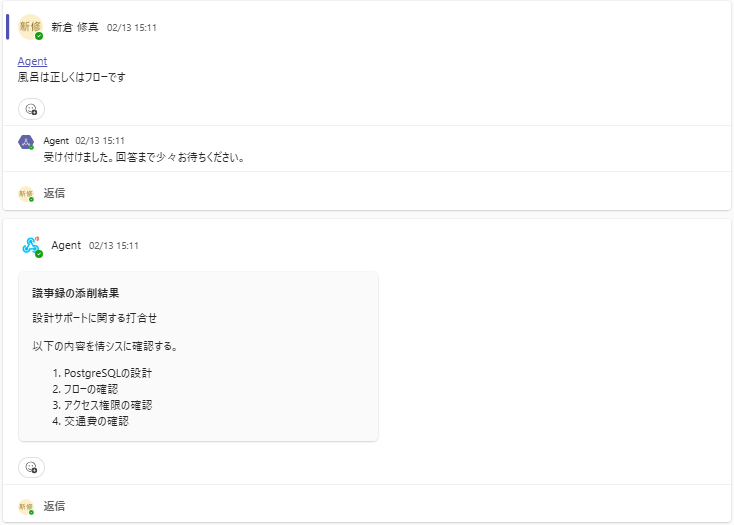
4.その後Agentは今回行った誤字修正をMemoryに保存します。
Memoryは以下画像の様に保存されます。
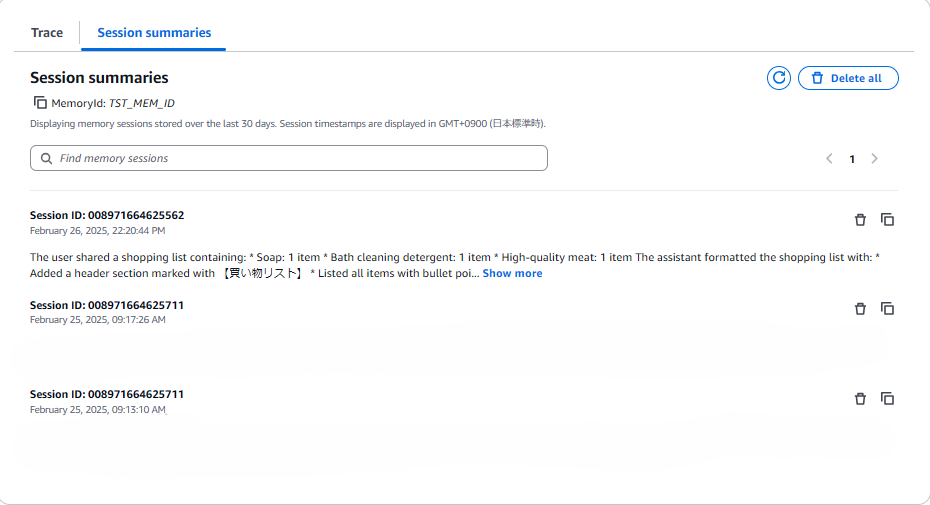
5.一度修正した文言は次回以降ユーザーが確認する必要はありません。Memoryを参照し自動で誤字が修正されます。
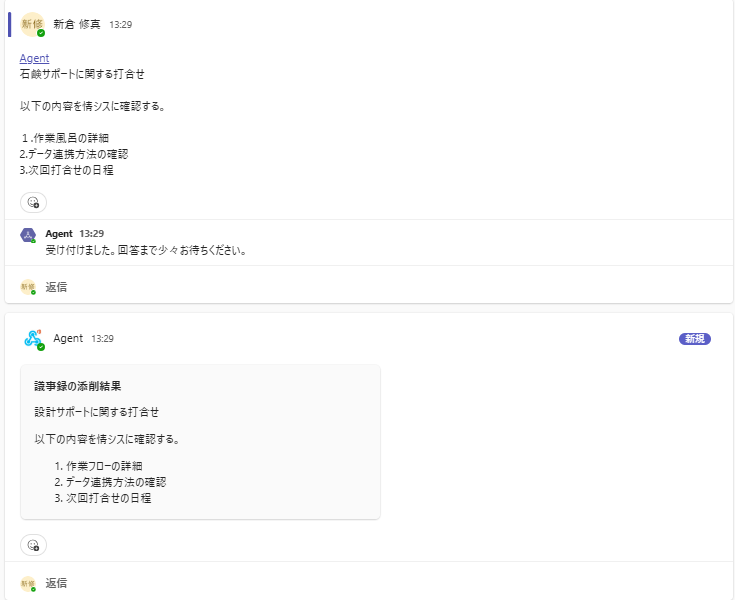
ユーザー入力機能と組み合わせることで、Memory 機能をより効果的に活用できると感じました。
議事録修正のユースケース以外にも、例えば有給の残数を取得する Agent に「私の有給の残数はいくつですか?」と初めて質問した場合、Agent はユーザーの社員番号を確認する必要があります。
しかし、Memory 機能を活用すれば、次回以降はユーザー ID をもとに Memory に保存された社員番号を照会し、追加の入力なしで有給の残数を取得できるようになります。
このように、ユーザーごとに異なる情報を活用して回答を生成する必要があるユースケースでは、Memory 機能を用いることで、よりパーソナライズされた応答が可能になります。
いかがだったでしょうか?一見便利そうなMemory機能ですが、有効化した際の消費Tokenの増加やMemoryが増えたときの回答精度などまだまだ検証の必要が多くあります。
この機能以外にも日々更新され、追加されている機能はまだまだあります。引き続き情報をアップデートし、皆様に共有していきます。