

クラウド活用の「共通言語」を整備
ガイドライン策定でAI活用にも対応可能なインフラ指針を確立
はじめに
こんにちは!クラウド活用推進担当の安田です。
今回は、社内で定期的に開催している勉強会の資料を、AIで要約してサマリを作れたら便利だと思い、実際に試してみました。
題材は、社内で開催した「re:Invent 2025 recap」の録画と、そのときに使用されたスライドのPDFファイルです。PDF資料と動画を統合して要約する方法を3パターンで比較し、それぞれの情報回収の精度、処理速度、蓄積能力を検証しました。
特に、「PDFにしか書かれていない情報」と「動画でしか補足されていない情報」を分けて出力する(=出所の誤帰属を防ぐ)観点で比較しています。
目次
- 比較する3手法
3手法の処理方法比較
比較1-1:PDFからの詳細な定量情報の回収
比較1-2:PDFからの概念・思想的な情報の抽出
比較2:実務的な補足情報(動画での口頭補足)
比較3:スケーラビリティ(蓄積能力) - 実例:3手法の出力結果比較
- 最後に
比較する3手法
今回検証する3つの手法を、まず一覧で比較します。
3手法の処理方法比較
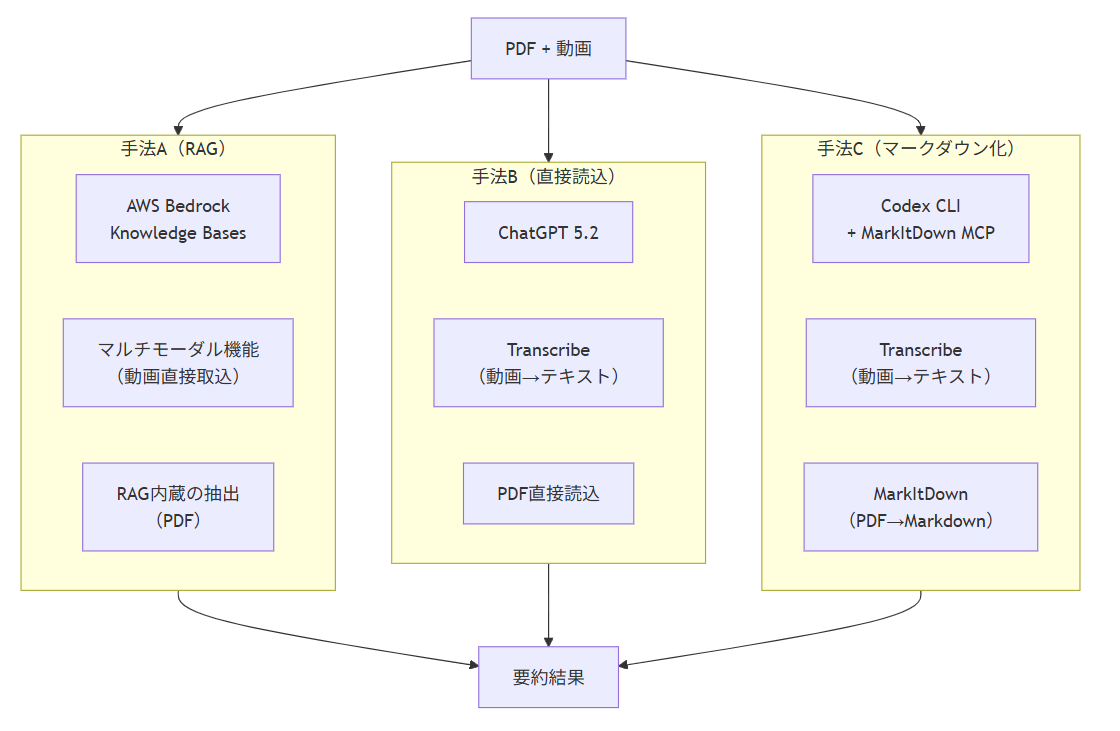
| 項目 | 手法A(RAG) | 手法B(直接読込) | 手法C(マークダウン化) |
|---|---|---|---|
| 実装環境 | AWS Bedrock ナレッジベース |
ChatGPT | Codex CLI + MarkItDown MCP |
| 使用モデル | Claude Sonnet 4.5 | ChatGPT 5.2 | ChatGPT 5.2 |
| 動画処理 | マルチモーダル(動画直接) | Transcribe | Transcribe |
| PDF処理 | RAG内蔵の抽出 | 直接LLMに投入 | MarkItDownでマークダウン化 |
注記:手法B(直接読込)・手法C(マークダウン化)は同じモデル(ChatGPT 5.2)を使用しています。手法A(RAG)はBedrock Knowledge Basesの制約上、Claude Sonnet 4.5を使用しています。
なぜこの3手法を選んだのか?
本来であれば、公平な比較のために同じモデル(例:Claude Sonnet 4.5)で統一すべきですが、今回は現在の自身の環境の中から使用可能なものを選択しました。
・Bedrock:AWS環境での統合やRAG構築を想定し、将来的な拡張性を評価するため採用
・ChatGPT:社内で既に導入されており、すぐに利用できる環境があった
・Codex CLI:開発環境として既にセットアップ済みで、MCPサーバーとの連携も可能だった
手法A:RAG(Bedrock Knowledge Bases マルチモーダル)
特徴:
・動画を直接取り込み可能(文字起こし不要)
・映像情報も活用可能
・RAGとの統合が容易で、検索機能を実装できる
制約:
・Bedrock Knowledge Basesの設定が必要
・対応リージョンが限定的
向いているケース:将来的に社内ナレッジ検索として運用したい場合
手法B:直接読込(ChatGPT + Transcribe)
特徴:
・最速で要約を作成できる
・Transcribeで文字起こししたテキストとPDFを直接LLMに投入
・MCP設定不要で、ChatGPTにファイルをアップロードするだけで開始可能
制約:
・PDFの構造情報(箇条書き、表、見出し)が失われやすい
・定量情報(数値、サービス名の列挙)の欠落リスクが高い
向いているケース:今日中に要約が必要な緊急時、または初めて試す場合
手法C:マークダウン化(Codex CLI + MarkItDown MCP + Transcribe)
特徴:
・PDFをMarkdown形式に変換してからLLMに投入
・箇条書き、見出し階層、注記を保持しやすい
・詳細な定量情報の回収に強い
制約:
・MarkItDownでの変換ステップが必要
・表の構造は完全には保持されない
向いているケース:定期的な勉強会の要約で、品質を重視したい場合
補足:動画処理とPDF処理の技術詳細
動画処理:マルチモーダル vs Transcribe
Amazon Transcribe(以下、Transcribe):
AWSが提供する音声認識サービスで、動画や音声ファイルを自動的にテキストに変換します。機械学習により高精度な文字起こしが可能で、タイムスタンプや話者識別にも対応しています。
マルチモーダル機能(手法A):
Amazon Bedrock Knowledge Basesのマルチモーダル機能(2025年11月30日GA)は、動画・音声・画像を自動的にテキスト化し、検索可能にする機能です。動画の映像・音声を自動解析してテキスト化し、元データとの紐付けを管理します。(参考:公式発表)
Transcribeでの文字起こし(手法B(直接読込)・手法C(マークダウン化)):
手法B(直接読込)・手法C(マークダウン化)では、事前にTranscribeで動画を文字起こししてからLLMに投入します。今回の検証では以下の条件で実施しました。
・動画:121MB、約50分
・処理時間:約4分
・コスト:約$1.3
・出力形式:JSON(ダウンロード可能)
PDF処理:直接読込 vs MarkItDown
PDFを直接LLMに読ませた場合の課題(手法B):
・箇条書きの崩れ:「・サービスA ・サービスB」→「サービスA サービスB」(区切りが消失)
・表の構造喪失:3列の表が1行のテキストに変換され、対応関係が不明に
・注記の欠落:ページ下部の「※制限事項」が読み取られない
・見出しの消失:セクション構造が平坦化され、階層が分からない
・表の構造喪失:3列の表が1行のテキストに変換され、対応関係が不明に
・注記の欠落:ページ下部の「※制限事項」が読み取られない
・見出しの消失:セクション構造が平坦化され、階層が分からない
MarkItDownによる改善(手法C(マークダウン化)):
MarkItDownは、Microsoftが開発したツールで、PDF・Word・Excel等をMarkdown形式に変換します。Markdown形式はLLMが効率的に処理でき、マークダウン化されたテキストにより精度向上とコスト削減が期待できます。詳細な特徴は手法C(マークダウン化)の説明を参照してください。
注意:PDFからの変換では表の構造は完全には保持されません。表の内容は抽出されますが、列の区切りが失われる場合があります。
実例:3手法の出力結果比較
3手法に以下の指示を与えた結果を比較します。
指示内容:
PDF資料と動画の内容を統合して要約してください。 制約条件: - PDFにのみ書かれている情報 - 動画でのみ補足されている情報 を必ず区別して書くこと。 出力形式: 1. 全体概要(3行以内) 2. PDF由来の重要ポイント(箇条書き) 3. 動画由来の重要ポイント(箇条書き) 4. 両方を踏まえた最終的な結論
比較1-1:PDFからの詳細な定量情報の回収
⚠️ 評価の観点:この比較は「単発の要約における詳細な定量情報の回収」を評価しています。手法Aも情報を出力していますが、参加者数や対応ランタイムなどの具体的な数値は含まれていませんでした。手法Aの強みである「蓄積・検索機能」は比較3で評価します。
PDFに記載されている定量情報(数値データ)を正確に回収できているかを比較します。
| 項目 | 手法A(RAG) | 手法B(直接読込) | 手法C(マークダウン化) |
|---|---|---|---|
| 参加者数 | ✗ 詳細な数値なし | ○ 約6万人 | ◎ 60,000人 |
| 協賛社数 | ✗ 詳細な数値なし | ✗ 詳細な数値なし | ◎ 401社 |
| セッション数 | ✗ 詳細な数値なし | ○ 3,100以上 | ◎ 3,100+ |
| Lambda Durable Functions 対応ランタイム |
✗ 詳細な数値なし | ✗ 詳細な数値なし | ◎ Node.js 22/24 Python 3.13/3.14 |
| Database Savings Plans 記載のないデータベース関連サービス |
✗ 詳細な数値なし | ✗ 詳細な数値なし | △ 「対象外サービス」と誤記 (正:記載のないサービス) MemoryDB, Oracle Database@AWS |
注記:「✗ 詳細な数値なし」は、該当する詳細情報が出力に含まれていないことを示します。手法A(RAG)は概要レベルの情報(例:Database Savings Plansの対象サービス一覧)は出力していますが、具体的な数値や詳細な列挙は含まれていませんでした。
ポイント:詳細な定量情報の回収では、手法C(マークダウン化)が最も多くの項目を回収できました。手法A(RAG)は概要レベルの情報は出力していますが、参加者数や対応ランタイムなどの具体的な数値は含まれていませんでした。手法B(直接読込)は一部回収できましたが、詳細な列挙は抜けやすい傾向があります。ただし、手法C(マークダウン化)でも誤記があり、完璧ではありません。
比較1-2:PDFからの概念・思想的な情報の抽出
PDFに記載されている概念的・思想的な情報(数値ではなくメッセージや考え方)を抽出できているかを比較します。
| 項目 | 手法A(RAG) | 手法B(直接読込) | 手法C(マークダウン化) |
|---|---|---|---|
| Renaissance Developerの 5つの資質 |
◎ 明確に列挙 (好奇心、システム思考、 コミュニケーション、 オーナーシップ、博学者精神) |
○ 言及あり (詳細は省略) |
✗ 言及なし |
| AIと開発者の関係性 (思想的メッセージ) |
△ 「絶対にない (Absolutely not)」と強調 (正:"絶対に"という 強調はされていない) |
○ 「強いメッセージ」 と概要のみ |
✗ 言及なし |
| 全体テーマの抽出 | Renaissance Developer に焦点 |
Agentic AI を中心テーマと明示 |
AI(エージェント) 中心と記載 |
注記:手法A(RAG)は他の2手法と異なり、Claude Sonnet 4.5を使用しています(手法B・Cは ChatGPT 5.2)。この要約内容の違いは、使用モデルの特性による可能性があります。
ポイント:概念・思想的な情報の抽出では、手法A(RAG)が「Renaissance Developerの5つの資質」を明確に列挙できています。一方、手法C(マークダウン化)は定量情報に強いものの、こうした抽象的なメッセージは省略される傾向があります。ただし、手法A(RAG)でも「Absolutely not」の解釈に誤りが見られるなど、完璧ではありません。
比較2:実務的な補足情報(動画での口頭補足)
動画では、PDFに記載されていない実務的な補足情報が口頭で説明されています。
| 項目 | 手法A(RAG) | 手法B(直接読込) | 手法C(マークダウン化) |
|---|---|---|---|
| Lambda Durable Functions リージョン制限 |
✗ 詳細情報なし | ✗ 詳細情報なし | ◎ 大阪未対応 2Q見込み |
| re:Invent会場 現地の実感値 |
△ 開催日・開催地のみ | ○ キーノートの構成 (思想・メッセージ重視) |
◎ 会場間距離 ホテル品質等 |
ポイント:動画での口頭補足は、手法A(RAG)では詳細情報が少なく、手法B(直接読込)・手法C(マークダウン化)で差が出ました。手法B(直接読込)は概要レベルの情報(キーノートの構成)、手法C(マークダウン化)は具体的な数値(会場間距離、時期見込み)まで回収できています。
比較3:スケーラビリティ(蓄積能力)
資料が増えた場合の対応能力を比較します。
| 項目 | 手法A(RAG) | 手法B(直接読込) | 手法C(マークダウン化) |
|---|---|---|---|
| 初期セットアップ | △ Knowledge Bases設定 S3バケット準備 |
◎ 不要 ChatGPTのみ |
○ MCP設定 Codex CLI導入 |
| 蓄積可能な資料数 | ◎ 無制限 (S3バケット) |
△ 数件程度 (コンテキスト制限) |
△ 数件程度 (コンテキスト制限) |
| 過去資料の自動検索 | ◎ 自然言語で検索可能 (RAGが自動取得) |
✗ 手動で投入が必要 | ✗ 手動で投入が必要 |
| 複数資料の横断分析 | ◎ 可能 (例:過去3年の傾向分析) |
△ 限定的 (数件まで) |
△ 限定的 (数件まで) |
| 資料が増えた場合 | ◎ 検索精度が向上 | ✗ コンテキストオーバー | ✗ コンテキストオーバー |
ポイント:手法B(直接読込)は初期セットアップが不要で試しやすく、手法A(RAG)は資料の蓄積に強く、過去の勉強会資料を自動検索・横断分析できます。手法B(直接読込)・手法C(マークダウン化)でも過去資料を手動で投入すれば参照できますが、コンテキスト制限により一度に処理できる資料数に限界があります。資料が10件以上蓄積される見込みなら、手法A(RAG)が最適です。
手法A(RAG)の特徴的な使い方:資料を蓄積することで、単なる要約を超えた活用が可能になります。
横断検索の例:
・「過去の勉強会でLambda Durable Functionsについて取り上げた資料はありますか?」
・「Database Savings Plansの対象サービスについて言及している資料を全て教えてください」
・「re:Invent 2024と2025でAI関連の発表内容を比較してください」
このように、手法A(RAG)は資料が増えるほど「社内ナレッジベース」としての価値が高まります。一方、手法B(直接読込)・手法C(マークダウン化)は単発の要約には優れていますが、過去資料の横断検索には向いていません。
参考:各手法の詳細な出力結果
比較1・2で評価した各手法の実際の出力内容を以下に示します。
▼ 手法A(RAG)の詳細な出力結果を見る
1. 全体概要
AWS re:Invent 2025に関連する内容で、Renaissance Developerの資質(好奇心、システム思考、コミュニケーション、オーナーシップ、博学者精神)と、新サービス「Database Savings Plans」(最大35%のデータベースコスト削減)が紹介されています。AIが開発者を時代遅れにすることはなく、むしろ開発者の重要性が強調されています。
2. PDF由来の重要ポイント
・Renaissance Developer(ルネサンス・デベロッパー)の5つの資質
・AIに対する姿勢:「AIは私を時代遅れにするのか?」という問いに対して「絶対にない(Absolutely not)」と回答
・Database Savings Plans:最大35%削減、対象サービス一覧
3. 動画由来の重要ポイント
・AWS re:Invent 2025イベント情報:開催日、開催地
・イベントは未来的なビジュアルとネオンライト、ラスベガスのランドマーク(フリーモントストリート、パリスラスベガスホテル&カジノなど)がフィーチャーされている(※根拠不明)
・日本のAWSトップエンジニアが紹介されている
4. 最終的な結論
AI時代における開発者の役割が再定義されています。AIが開発者を置き換えるのではなく、「Renaissance Developer」として進化することが求められています。
▼ 手法B(直接読込)の詳細な出力結果を見る
1. 全体概要
AWS re:Invent 2025は「Agentic AI」を中心テーマに、AIエージェントの実用化とそれを支える基盤・サービスの拡充が強く打ち出された。PDFではイベント全体像と技術アップデートが体系的に整理され、動画では現地の臨場感やキーノートのメッセージ性が補足された。
2. PDF由来の重要ポイント
・AWS re:Invent 2025は参加者約6万人、3,100以上のセッション
・今回の中心テーマは Agentic AI。全セッションのうち1,000以上がAI関連
・Werner Vogelsのキーノートで示された「ルネサンス・デベロッパー」
・Lambda Durable Functions:最大1年の待機状態を持つワークフロー実装が可能
・Database Savings Plans:DB利用料を最大35%削減可能
・Amazon S3 Vectors:S3上のデータに直接ベクトル検索を実行
3. 動画由来の重要ポイント
・キーノートは従来よりテクニカル色が薄く、思想・メッセージ重視の構成
・「AIによって開発者の仕事がなくなるのでは?」という問いに対する強いメッセージ
・オープニングキーノートは1時間前から長蛇の列
・セッション参加感として「1日3〜5セッションでも非常に密度が高い」
4. 最終的な結論
PDFは「Agentic AI時代への本格移行」として体系的に整理し、技術・サービスの全体像を提供。動画は「なぜその方向に進むのか」という思想面と現地の熱量を補完。両者を合わせることで、AWSの狙いは人が主導する自律型システム時代の確立にあることが明確になる。
▼ 手法C(マークダウン化)の詳細な出力結果を見る
1. 全体概要
AWS re:Invent 2025の「参加レポート」と「注目アップデート」をまとめた内容です。技術面はAI(とくにエージェント)中心で、サーバレス・DBコスト・検索・Kubernetes・セキュリティ・ネットワークに新要素が増えています。動画では、資料の要点に加えて"現場感のある補足"と、具体的な使いどころの示唆が追加されています。
2. PDF由来の重要ポイント
・参加規模の定量情報:参加者数60,000、協賛社数401、セッション数3,100+、日本からの参加者数1,900+
・AI関連の比重:3,100+セッションのうち1,000+がAI関連
・Lambda Durable Functionsの対応ランタイムが明記:Node.js 22/24、Python 3.13/3.14
・Database Savings Plansの具体情報:最大35%削減、対象サービスの一覧(Aurora/RDS/DynamoDB/ElastiCache/DocumentDB/Neptune/Keyspaces/Timestream/DMS等)、対象外(MemoryDB、Oracle Database@AWS)
・Amazon S3 Vectorsの留意点として「ハイブリッド検索できない」旨が明記
・Amazon EKS Capabilitiesで利用可能なツール名が明記:Argo CD、ACK、kro
・Frontier Agentsは発表時点で「プレビュー」「us-east-1のみ」と明記
3. 動画由来の重要ポイント
・会場の実感値:会場間が遠く「最遠同士で約4km、徒歩で約1時間」、シャトルバスは概ね10–15分
・宿泊・現地体験の生の情報:ホテルの品質感(例:シャワーが弱い、ハウスキーピングが期待通りでない等)
・体験型展示の具体例:Kiroをモチーフにした体験(お化け屋敷)、AIで香水提案→調香師が作る体験、無料タトゥー/ピアス
・Lambda Durable Functionsの補足:大阪リージョンは未対応で「来年の2クォーター見込み」
・AWS Capabilities by Regionの使いどころ補足:大阪で未提供の例としてAmazon Detectiveが「拡張予定なし」と明示
・Werner Vogelsについて「今年でキーノートのスピーカー引退」など、人物・状況の補足
4. 最終的な結論
AI(エージェント)中心の流れは前提として、実務では「どのリージョンで使えるか」「プレビューか」「コスト/運用がどう変わるか」を起点に、Lambda Durable Functions・Database Savings Plans・S3 Vectors・EKS Capabilities・GuardDuty拡張・PrivateLink cross-regionを"自社/案件の課題に刺さる順"で小さく検証していくのが最短です。
最後に
PDF+動画の統合要約では、目的に応じた手法の使い分けが重要です。
今回の検証結果のまとめ:
・単発要約の精度:手法C(マークダウン化)が詳細な定量情報の回収で優位
・処理速度:手法B(直接読込)が最速
・蓄積・検索:手法A(RAG)のみ対応、資料が増えるほど価値向上
選択の目安:
・初めて試すなら、手法B(直接読込)で手軽に開始(MCP設定不要)
・資料が月1〜2件程度なら、手法C(マークダウン化)で高品質な要約を作成
・資料が10件以上蓄積される見込みなら、最初から手法A(RAG)で検索基盤を構築
今回の検証では手法A(RAG)の単発要約精度が低めでしたが、これはナレッジベースの設定(チャンクサイズ、検索パラメータ、プロンプト等)を最適化することで改善の余地が大きいと考えています。また、手法A(RAG)の本質的な価値は「蓄積と検索」にあり、資料が増えるほど真価を発揮します。
どの手法でも要約が100%正確とは限りません。今回も「対象外サービス」という誤記や、定量情報の欠落が見られました。要約の内容は信用しすぎず、必ず元のPDF・動画を確認することをおすすめします。
ここまで読んでいただき、ありがとうございました。