

脱レガシーで変化に強い基幹システムの基盤を実現
長年の信頼と“現場理解力”による伴走支援
Amazon Bedrock ナレッジベースのデータソースを
Confluenceにする
Confluenceにする
こんにちは。クラウド活用推進担当の栗田です。
社内文書などの情報を生成AIの回答に含めてもらうことをRAGと言いますが、
Amazon Bedrockのナレッジベースを活用すると簡単にできます。
ナレッジベースのデータソースとして、Amazon S3を使用するのが簡単ですが、
今回は、自社で活用しているConfluenceを使用してみましたので、手順を紹介します。
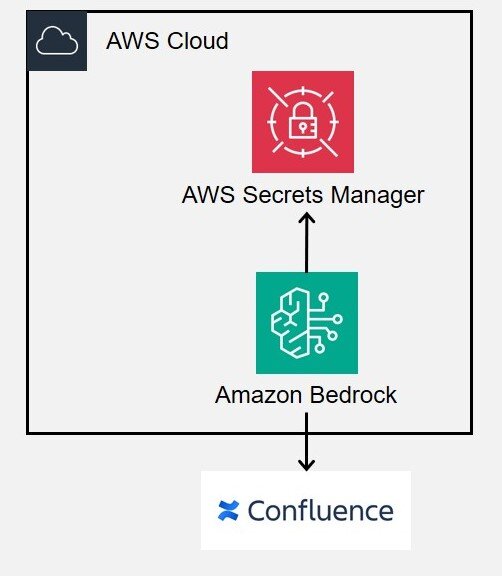
今回作成したRAGの構成図です。
今回の構成ではAWSコンソール上でのRAG検索しかできないですが、
例えばLambdaなどを活用すると、チャットツールなどで対話形式でRAGを実現できると思います。
・AWSのアカウントがあること
・Confluenceのアカウントがあること
Amazon Bedrockのモデルアクセスにて、使用するベースモデルのアクセスが有効になっている必要があります。
手順については下記を参照してください。
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/model-access-modify.html
※今回の手順では、下記ベースモデルを使用しています。
・Titan Embeddings G1 - Text
・Claude
※私はリージョンをバージニア北部にしています。(東京リージョンよりベースモデルの選択肢が多いです)
Atlassianのアカウント管理ページにて、
「APIトークンを作成する」ボタンより、Bedrockと接続するためのAPIトークンを作成します。
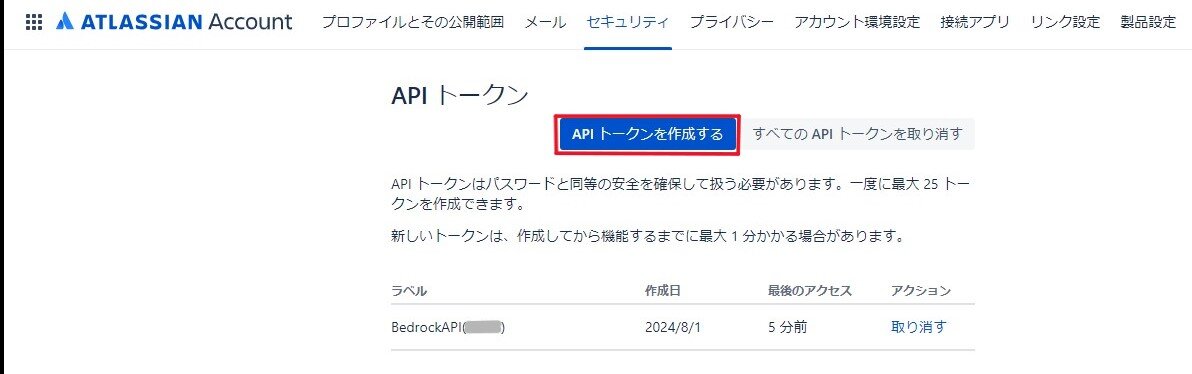
作成されたトークンは必ずコピペしておいてください。
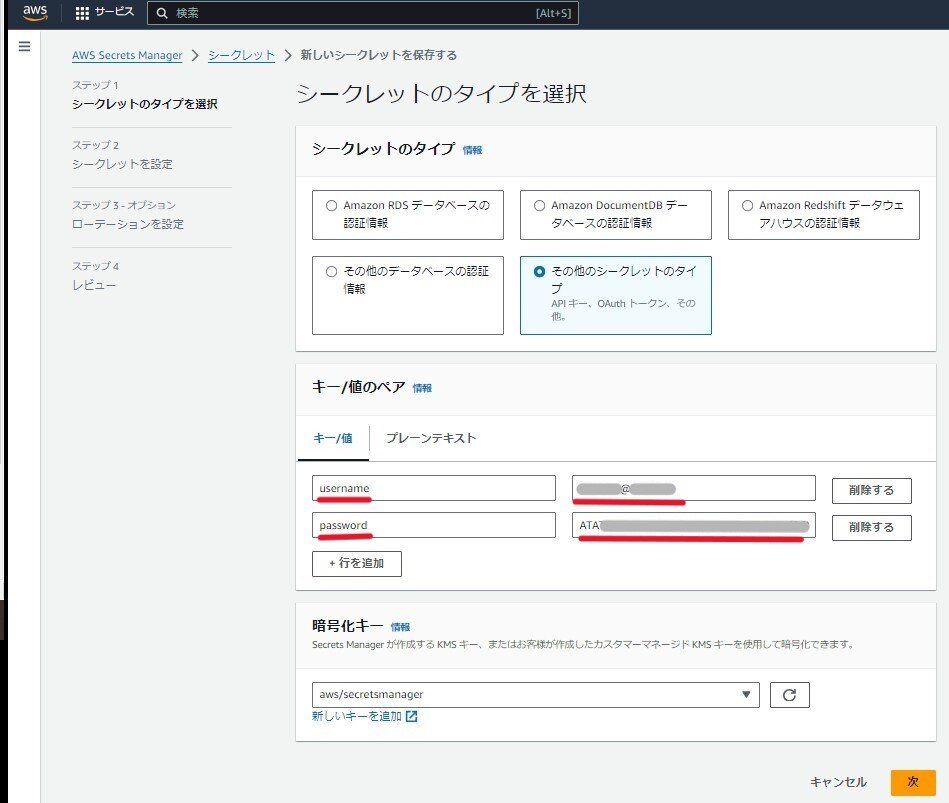
以下の情報を、AWS Secrets Managerに登録します。
| キー | 値 |
|---|---|
| username | Confluenceにログインする際のユーザーネームを記載 |
| password | 前項で作成したAPIトークンを記載 |
実際の登録画面は下記のようになっています。
AWS Secrets ManagerのARN(Amazon Resource Name)を次項で使用するので、
どこかにコピペしておいてください。
※ARNは、AWS Secrets Manager>シークレット>シークレット名 の画面上で確認できます。
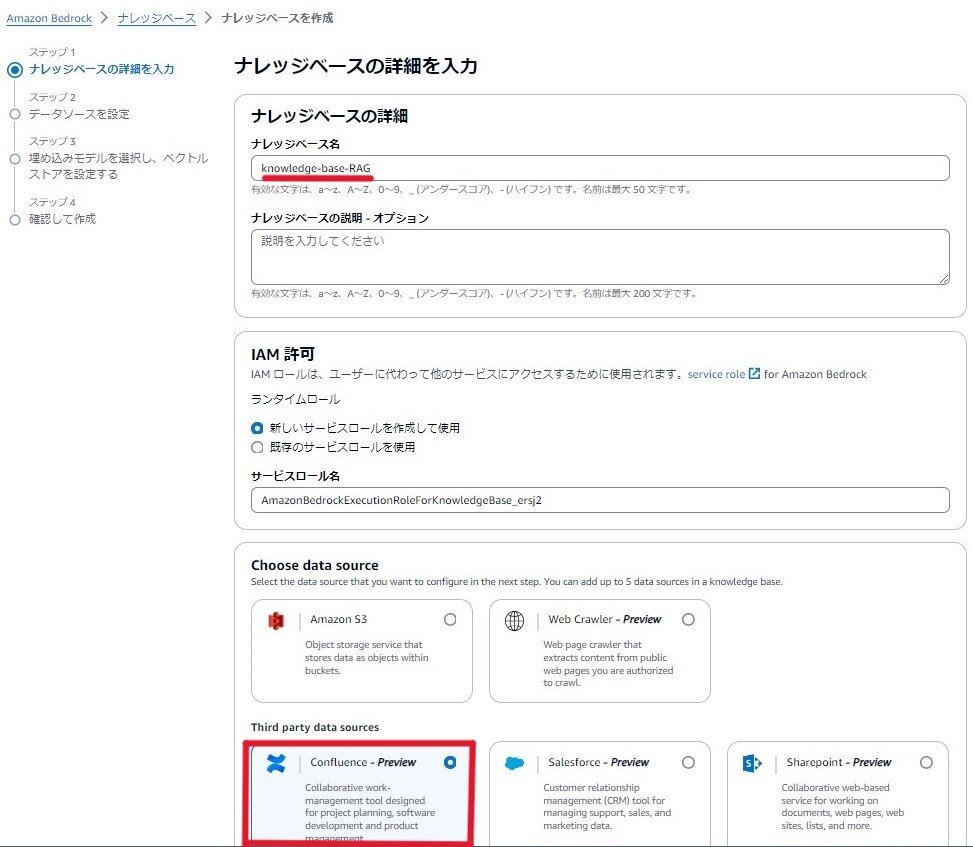
Amazon Bedrockにてナレッジベースを作成していきます。
1. ナレッジベース名を入力します。
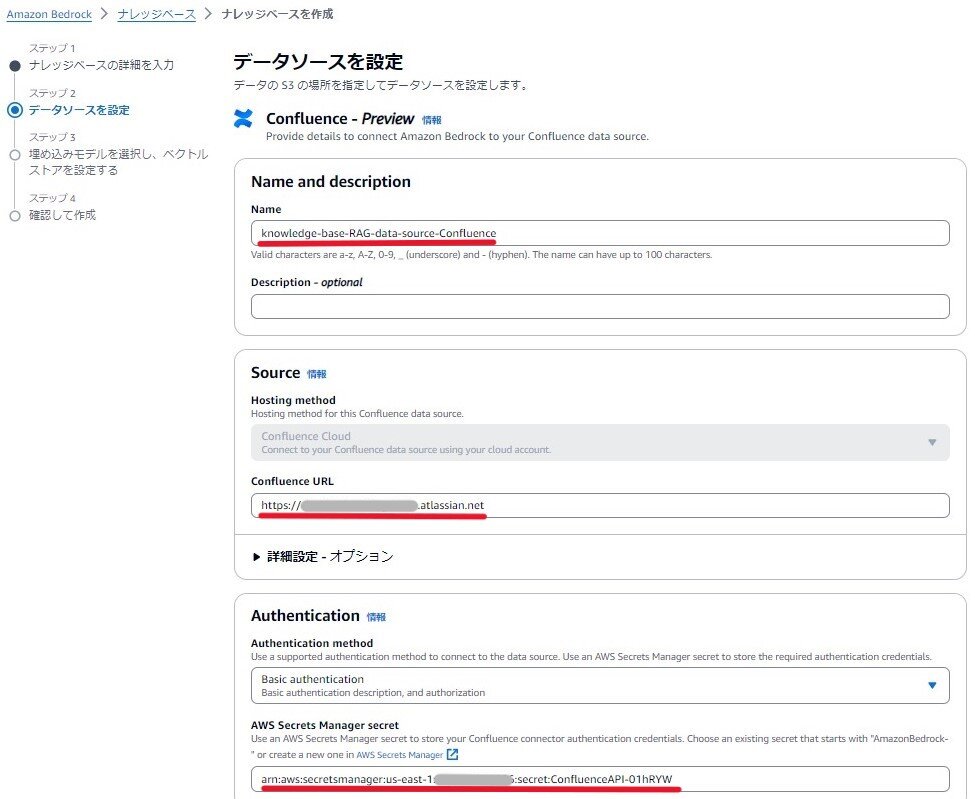
また、データソースは「Confluence」を選択します。
次にConfluence URLを入力します。多くの場合、「https://xxx.atlassian.net」のようになると思います。
次に前項で作成したAWS Secrets ManagerのARNを入力します。
私は「Titan Embeddings G1 - Text」を選びましたが、お好みでOKです!
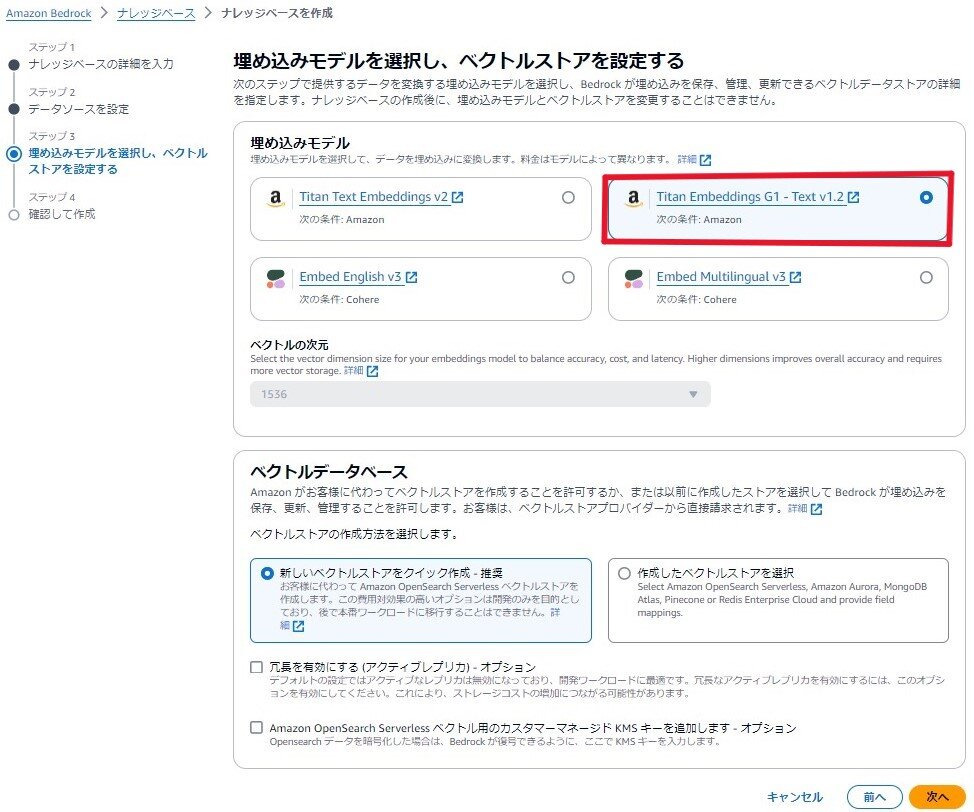
その他はデフォルトで良いので、そのままナレッジベースを作成します。
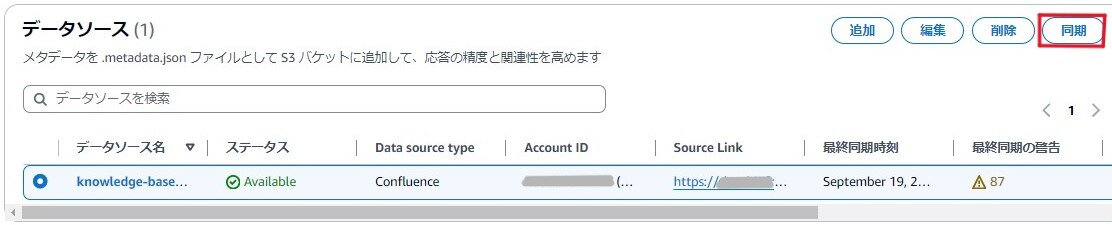
4. ナレッジベースの作成後は、データソースを同期しておいてください。
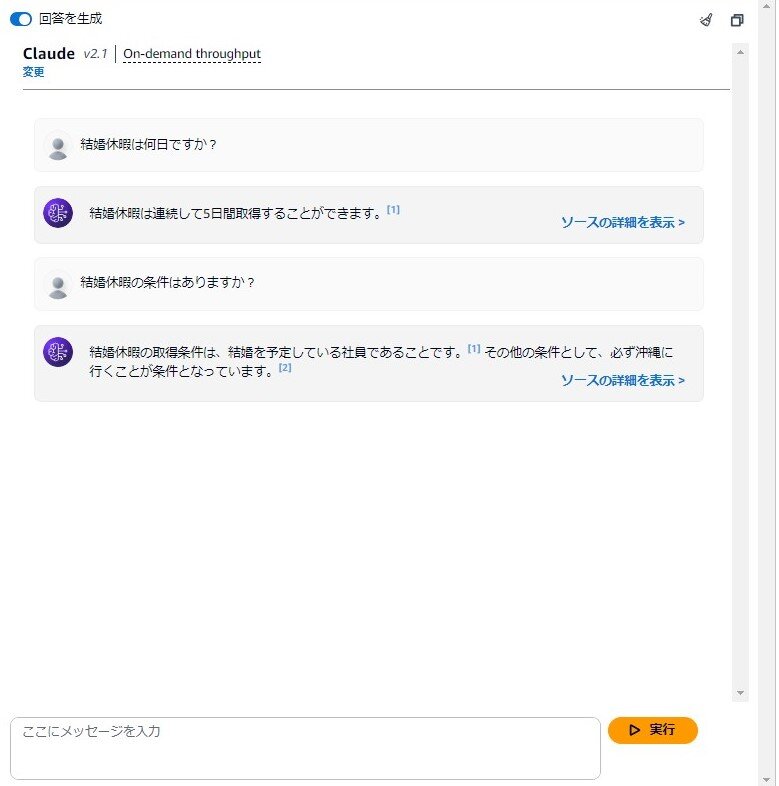
ナレッジベースをテストしてみると、Confluenceにアップロードしてある架空の社内規定の情報をちゃんと答えてくれました!
※これは架空の社内規定であり、DTSにこんな規定はありませんのでご安心ください。
今回、ナレッジベースを作成する際のベクトルデータベース※はデフォルトの「OpenSearch」になっていますが、1日5ドル(700円)くらいかかるので注意してください。
勉強や検証目的であれば、使用後は忘れずに削除してください。
※ベクトルデータベースとは
データを数値の配列(ベクトル)として保存し、効率的に検索や類似性分析を行うためのデータベース
RAGって便利ですね~。今後色んな目的で使われていくのだろうなと思いました。
社内文書などをConfluenceに格納している方の参考になれば幸いです。
あとはコストの面で課題があります。
OpenSearchに関して、もう少しコスト削減できたらなぁと感じました。
OpenSearchの代わりに、Auroraなども選択できるので、いつか試してみたいと思います。